
Today we’re announcing the public beta of Freeplay: the end-to-end platform for software companies to ship great products with LLMs.
Now any business can get access to our collaborative, enterprise-ready tools for building, testing, and optimizing LLM-powered products. Freeplay has been in use by a small group of businesses for months, and we’re excited to open it up to a wider audience.
We first shared what we’re up to at Freeplay in late May, and we recently shared some of the big challenges that technology leaders across engineering, product & design are facing:
Building reliable systems to test & improve LLM responses, and to avoid risks from hallucinations & other bad behavior
Tuning prompts & other parts of LLM pipelines to shave down costs & improve margins
And, ultimately — the goal of every product team! — building the feedback loop needed to consistently improve the customer experience over time
Now, we’re happy to show how our product can help.
Why we’re building Freeplay
In our view, the last thing this ecosystem needs right now is another “developer tool.” Tools abound right now, but many are limited in scope and only useful to developers.
At the same time, LLMs are creating a paradigm shift. Developers are collaborating in new ways with colleagues across product, design, QA, and other domains to build products. LLMs decrease the barrier to entry for other roles to get involved, and many LLM product use cases demand a new level of domain expertise to tune responses for accuracy and quality (vs. traditional software development or QA). We think this trend is going to continue: more people & roles will be empowered and capable to help ship software products to customers, working alongside developers who will continue to drive.
Like how Figma gave product development teams a better way to work together in the design process and leveled access to design artifacts, Freeplay wants to empower builders — developers and non-developers alike — to work together in a shared environment and rethink how software products get built with LLMs. We know we’re still in the early days and we’re excited to see where the future takes us all.
How Freeplay works
Freeplay gives teams an end-to-end workflow to iterate on prompts, monitor results, curate & label data for testing or fine-tuning, conduct evaluations using both automated & human methods, and automate testing. Together these create a flywheel for continuous monitoring & improvement.
Read on for more details on how Freeplay can be used, or check out the video on our home page.
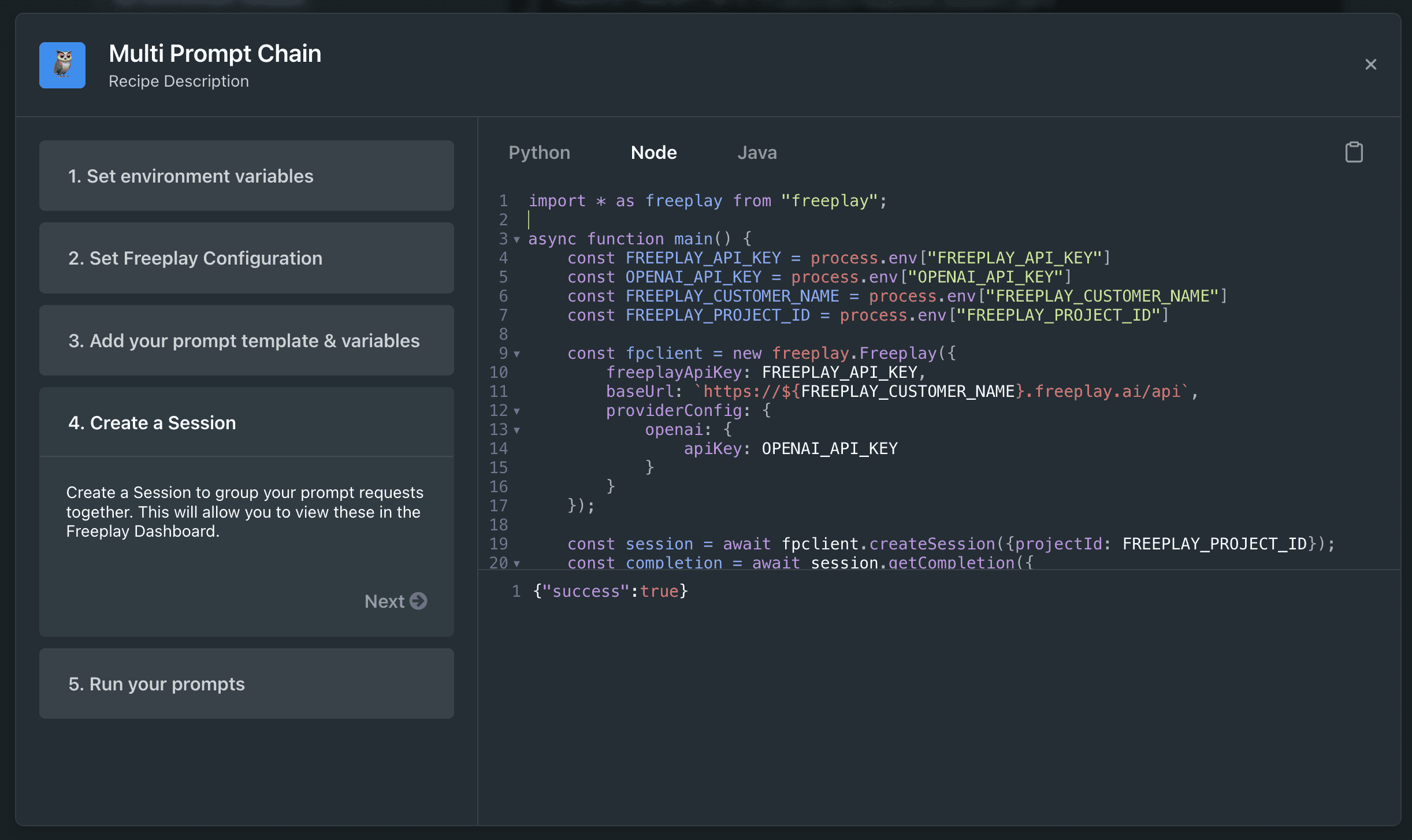
Manage, version & deploy your prompts
A simple integration with our developer SDKs lets you manage each new iteration of a prompt/model combo as a version in Freeplay. We give engineers and their collaborators alike the ability to adjust prompts and swap out models or providers in any environment (development or production). We make this possible without diving back into the codebase for each change, mirroring the flexibility of other server-side experimentation tools. This turns your working code into a playground, so you can get realistic results from simple prompts, chains & RAG pipelines when prototyping new ideas.

Monitor results, label & organize your data
The same integration records LLM requests/responses in Freeplay and surfaces them in an easy-to-use observability dashboard for the whole team. You can search, filter and inspect results to understand exactly what’s happening — including prompt versions, input variables & RAG contexts, LLM completions, costs, latency, and more.
One of the most helpful parts of using Freeplay instead of a separate observability tool is a fully integrated workflow to label results & curate data sets for testing, fine-tuning, and more. Any time someone from your team looks at a session in Freeplay — from development, staging, or production — it’s easy to apply custom labels or save a session as a test case. This makes it easy to build a comprehensive dataset for consistent testing and compare results as you iterate.

Combine the best of AI & human evaluations
Whether you’re working on a new iteration, running a routine integration test, or keeping an eye on production results, a key part of success building with LLMs is the ability to score & compare a representative set of examples. Freeplay combines the best of automated & human evaluation methods to make it easy to complete fast, accurate, relevant evaluations. The same custom-defined evaluation criteria used by your team members for labeling sessions can be deployed for automated evaluations, and the two work together to give you a feedback loop you can trust — with human-labeled examples providing correction/confirmation to AI evaluations. We also provide a range of tools for different types of evaluations, including for scoring single results, or human preference ranking for comparing multiple results.

Automate testing and quickly compare results
Once evaluations are configured & you’ve either curated or uploaded test cases, Freeplay makes it easy to automate the test process — whether during experimentation or as part of an ongoing integration test process. Our SDK lets you test your LLM features end-to-end within your code, so that you can generate realistic results repeatably and at scale. AI evaluators instantly score results, and you have the option to rely on those scores for a single run or compare results to prior versions for human preferences.

Developer Control
Freeplay provides developer SDKs for Python, Node.js, and Java (all JVM languages) that make it easy to integrate with your existing stack. Our goal with the SDKs is to make simple things easy, and anything possible. Basic methods make it easy to drop Freeplay in, and support for custom callbacks and overrides make it easy to customize when necessary.
Enterprise Ready From The Start
We’ve built Freeplay with mature product teams in mind. Role-based access controls & separate workspaces per feature/project make it easy for a whole organization to collaborate. Industry-standard security & privacy controls and single-instance deployment options give confidence your data is safe, and a self-hosted option — currently in a limited pilot — makes it possible to deploy Freeplay in a VPC for organizations with the highest level of compliance obligations. And Freeplay’s built for scale, ready to grow to millions of completions & more.
Expanding the Freeplay Team
As part of this announcement, we’re also making public our initial fundraising round co-led by Sarah Guo of Conviction Partners and Natty Zola of Matchstck Ventures, along with Exponent Founders Capital, The Ride Home Fund, and a collection of founders & executives both from established companies and those breaking new ground, including YouTube, Twitter, Sprout Social, Framer, Maze, Digits, Grain, Occipital, Firstbase and more.
We’re also continuing to grow our Colorado-based team. Check out our job postings here.
Free to get started
Starting today, product development teams can get access to a free trial of the public beta, and we’re continuing to work closely with early customers to help them get the most from the product. Joining our beta is a chance to shape the product direction as we continue to build quickly.
You can get access starting today from our home page.
Interested to follow along & keep up with learnings from across the LLM product development ecosystem? You can also sign up for our newsletter, which we’ve been publishing for ~6 months now to an insider group of builders, leaders and investors. It’s the best way to keep up with our blog, as well as industry highlights we include each time.
Categories
Product
Authors

Ian Cairns