
Today we’re announcing new agent evaluation and observability features that make it easier than ever to build and iterate on production-grade AI agents. Your whole team can now evaluate, observe, and iterate on your agents with confidence — without changing your orchestration layer, and regardless of whether you’ve written your own code or use popular frameworks. Lots of people have been trying to solve these problems and gluing together a range of tools to make it happen. Freeplay's new Agents features provide an integrated, well-lit path for your agent development ops.
If you’re part of a production software team building your own AI agents or agentic products and looking for a better way to run evals and improve your agents, you’ll want to keep reading.
We've helped companies building complex AI systems for years, but over the past 6 months the shift to seemingly everyone now building agents has been dramatic. What used to be a long-term R&D roadmap item for many companies has turned into an urgent priority. Many teams have quickly moved from “maybe someday” to “we need this yesterday” when it comes to deploying agentic systems into production.
Instead of applications built around single LLM prompts, many companies are now building multi-step agents and workflows: systems that chain prompts, call tools, and make branching decisions to produce a single output. (For the purposes of this post, we're using the word "agent" to describe both fully autonomous agents and multi-step workflows — Anthropic's great post outlines the differences.)
As these systems become more complex, so does the experimentation, testing and evaluation processes necessary to get them right. We constantly hear from people who said they could get by with DIY solutions when it came to single prompt apps, but who now feel urgency to get help debugging, testing, and improving on their agents. As one Freeplay customer recently told us:
“These problems were all a lot easier and we could get away with manual testing and using spreadsheets (when building single prompt applications). That's changed now that we're building agents.”
Agents in Freeplay
The same basic primitives and actions needed to build reliable prompt-centric systems are needed when building agents. That’s why we’ve added a new core concept to the Freeplay platform: Agents.
This new entity lets you group related traces, prompts, tools, datasets, and evals into a unified view — extending our current trace support and Test Runs feature, and making agent traces even more of a first class object in the Freeplay platform.
Watch this quick demo to see it all in action, and check out the docs here to get started.
The Challenges To Building High-Quality Agents
Anyone building agents will quickly run into a common set of challenges as they scale things up:
Observability is harder — Agent workflows span multiple prompts, tools, and branching decisions, not just single input-output pairs from a prompt. You need to see what happened, and the sequence in which it happened.
Debugging demands detailed traceability — Pinpointing failures requires step-level insights and monitoring. You need to be able to detect errors that occur at any step in an agent or workflow so you can take action.
Testing explodes in complexity — You need to evaluate outcomes and the individual steps taken to get there, and you need to be able to compare different variants, side-by-side, and at scale across a range of test cases. There’s no other way to know if you’re truly improving for customers.
Multiple levels of evaluation — To support both testing and production monitoring, you need evals that operate at multiple levels. Prompt-level evals help you measure quality and catch errors at individual steps, and agent-level evals help you assess the overall quality of task completion. Once you define evals for your agent, ideally you can run them both offline for testing and experimentation, and online for production monitoring — that way you know how well production matches your test scenarios.
Developer experience — Clean abstractions and flexible control to decide how to integrate become essential. You need to be able to adjust any part of your system, which means you don’t want developer tools that make lots of assumptions for you.
A Better Way to Build Production-Grade Agents
With Agents in Freeplay, you can now treat your agent as a testable, observable system, not just a loose collection of calls. This fully integrated set of tools makes it easy to gain confidence in how your agents are working, and then build the data flywheel you need for continuously improving your agents over time.
Agent-Level Evaluations
Define and run agent-level evals on top-level agent inputs and outputs, and then use prompt-level evals on the intermediate steps that occur along the way. These two levels of evaluation work together to let you quickly diagnose where any failures occur — for example with intent recognition or tool selection in a router prompt, or the final response quality from the agent.
Both prompt-level and agent-level evals in Freeplay can be run in offline experiments or tests, and on your production logs. This gives you visibility into how well your agents behave in the real world as well as with your test cases.
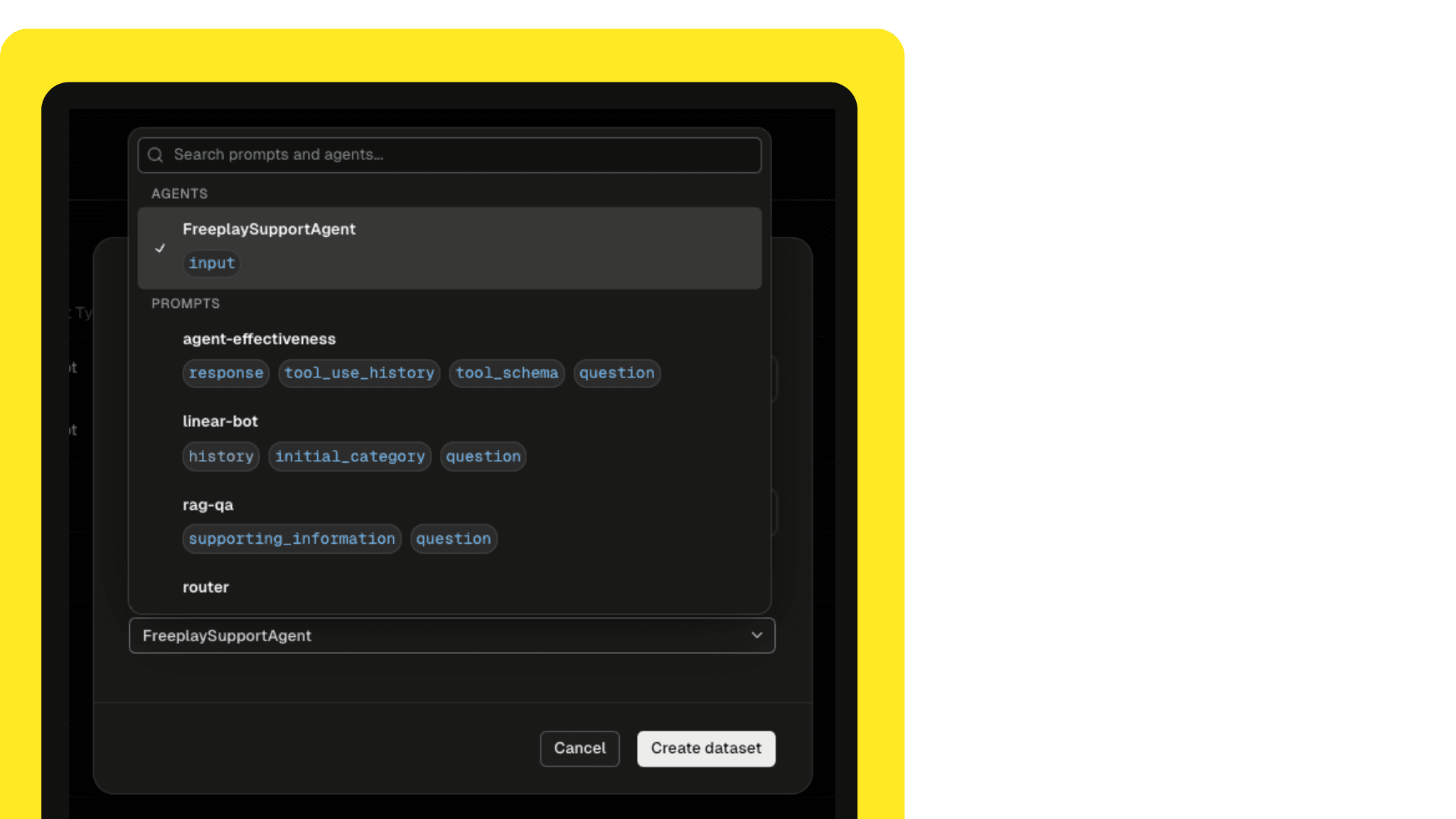
Agents Datasets
Curate datasets for testing end-to-end agent behavior, and separate prompt-level datasets to test specific steps. Simply pick a "target" when creating a new dataset, and Freeplay will help you format the dataset to easily use with that target agent or prompt. These different types of datasets give you the flexibility to test the whole system or isolate weak links.
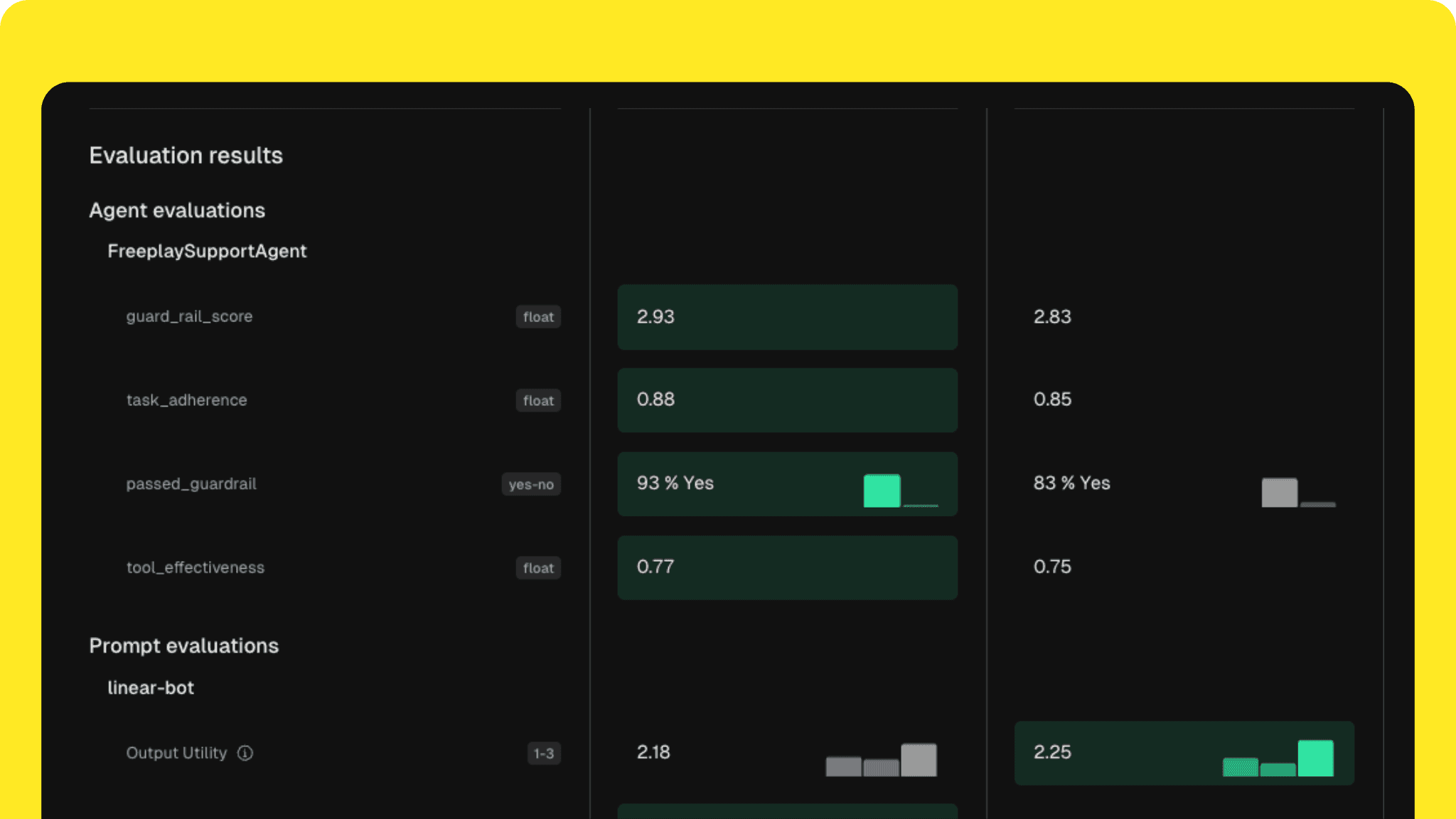
Agent Testing & Comparison
Run structured tests and experiments every time you version your system, whether you're making a prompt or model update, changing a tool definition, or updating your orchestration pipeline. Record results from your actual code so you can compare outputs, evaluate success rates, and drill into where things break.
The following screenshot shows a snapshot of how you can compare different versions of your agents side by side in Freeplay, using your own custom eval metrics to quantify which version is better.

Agent Observability
Log named traces every time your agent runs, and run evals on those logs to gain insight into quality and performance at scale. Quickly filter by agent, eval score, customer feedback, and more. Then drill in to see step-by-step prompt execution, tool calls, and eval results, all in a digestible format that anyone on your team can understand.

Flexible Developer Experience
All of this is possible using our SDKs or API with your existing orchestration layer. Whether that’s your own custom code or popular frameworks like LangChain, Google’s ADK, OpenAI’s Agents SDK, or similar. Just name your Freeplay trace to match the agent you’re running. The rest of these features then automatically work together to give your team an integrated workflow for building, testing, and shipping better agents with confidence.
Get started by checking out our Agents guide and the code samples here.
Building Better Agents - What’s Next
This is just another step toward improving Freeplay’s full set of solutions for your teams to build great AI products and agents. We’ve got more planned to help agent developers, including new tools to tune LLM judge prompts for agents, speed up human reviews and error detection, SDK updates, and faster solutions for early stage prototyping. If you’re curious to go deeper, we’d love to chat.
Current Freeplay customers can start using these agent features today.
And if you're interested to get started with Freeplay, you can sign up here.
First Published
May 29, 2025
Authors

Jeremy Silva
Categories
Product




