
At this point anyone building AI applications is likely familiar with the importance of Retrieval Augmented Generation (RAG). And they’re also likely familiar with the challenges of getting a reliable RAG system shipped to production.
It can be daunting! Especially in an enterprise setting where the stakes are high for both quality and compliance.
That’s why we’re excited to announce our partnership with MongoDB, and how we’re working together to help production software teams test & tune RAG features that work well at scale.
This post goes into detail for how to set up and then use Freeplay and MongoDB together to find and fix issues with RAG systems. The video at the end shows how it all comes together in practice.
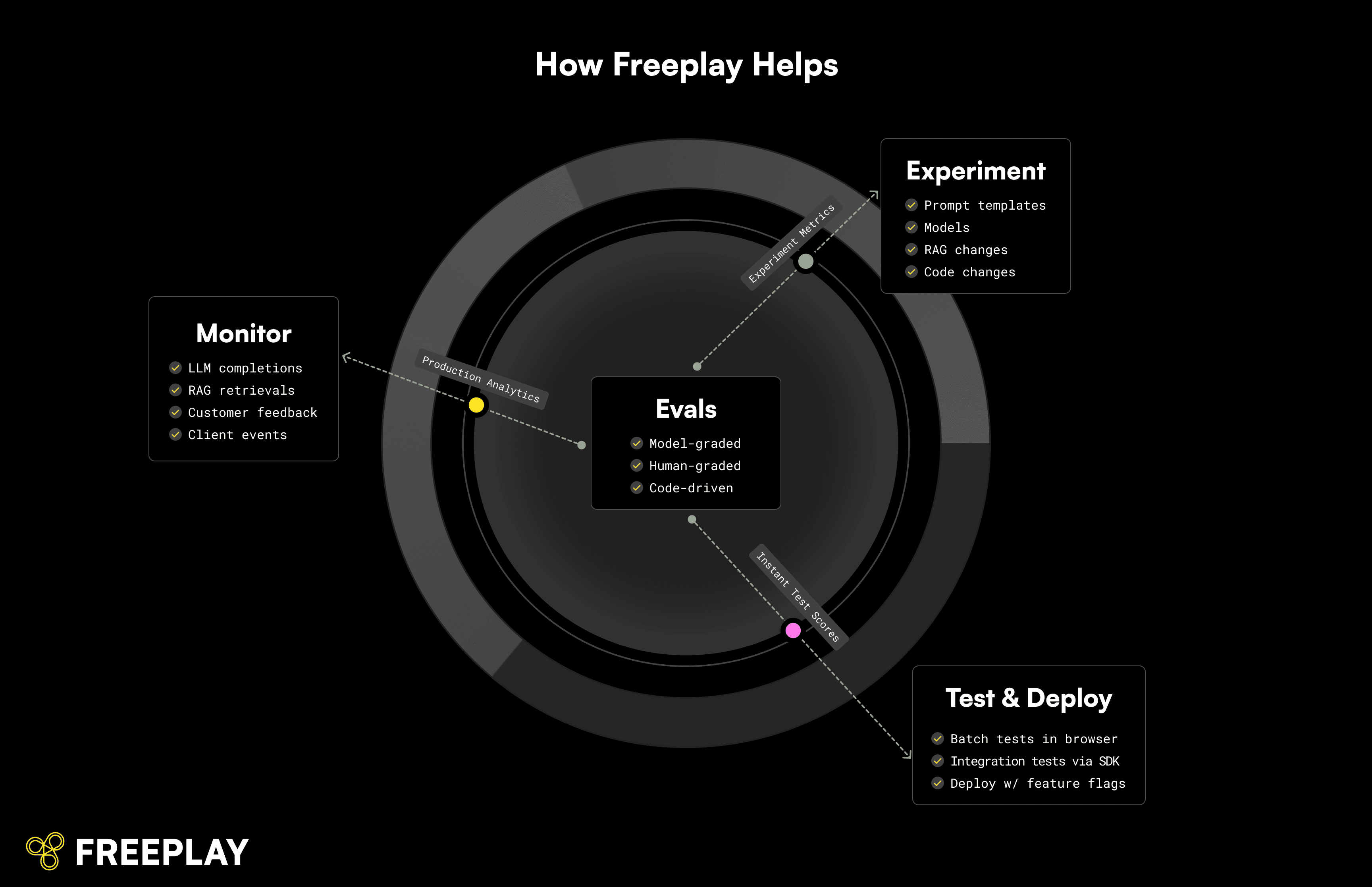
The Challenge
Getting RAG systems to perform well today often means a lot of experimentation, tuning, and optimization. This can be complicated by the fact that there are so many moving pieces that impact the ultimate customer experience for AI products, in particular:
Retrieval: Is your RAG pipeline finding the right content? If it’s not, what do you change? Chunk sizes, embedding strategy, ranking, etc. can all be adjusted, not to mention more advanced techniques from research.
Generation: Is the LLM doing what you want? If not, is it because of your prompt engineering? The model itself? Model parameters that you could adjust? Any tweak to one of those variables can have surprising impacts — positive or negative.
We hear from teams nearly every day who feel overwhelmed by all the variables involved, and more than a few who get so exhausted from all the experimentation that eventually they just decide to ship something — even if they know it’s not as good as they’d want.
And then: Even after you get a basic version working, you’re never “done.” Models change, underlying data changes, and results change for customers.
If you're building AI products, you need a system and process in place to help continuously uncover and fix issues. Everyone working in this space is looking for a better way.
What is Freeplay?
Freeplay gives product development teams the power to experiment, test, monitor & evaluate the use of LLMs in their products. Product teams use Freeplay to build better chatbots, agents, and to integrate LLMs into existing products. They choose Freeplay because it gives them a single tool to collaborate as a team across the product development lifecycle — and saves time & money.
Why we love MongoDB
MongoDB is a non-relational document database designed for large scale applications. It’s been around for years and it’s well-loved by developers.
For serious production generative AI use cases, it stands out because it’s already optimized for scale and high throughput/low latency workloads, and it’s easy to adopt for existing MongoDB customers. MongoDB Atlas is a developer data platform that provides a seamless integration between existing operational databases and vector search, enabling developers to use a common vendor and familiar interface for both functions.
When our team first tried testing out another open source vector database, it took a couple hours to get familiar with writing queries. With MongoDB, it took about two minutes. 🔥
Using Freeplay & MongoDB to Ship Great RAG Systems
In this post we’ll show how developers, product managers, domain experts and other collaborators work together to optimize a RAG system:
Quickly experiment with new prompts, models and RAG system changes
Run batch tests both in the Freeplay app and in code to test the parts of a RAG systems
Monitor & evaluate RAG retrievals and LLM completions across environments in realtime to detect quality changes
Review & curate datasets from observed data to continuously track & fix issues
This set of steps supports a continuous product optimization loop, and it’s core to how our customers use Freeplay.
Getting Set Up
For the purposes of this demo we are going to be building a RAG chat system over all our Freeplay blog posts and documentation. Here’s what the application architecture will look like.
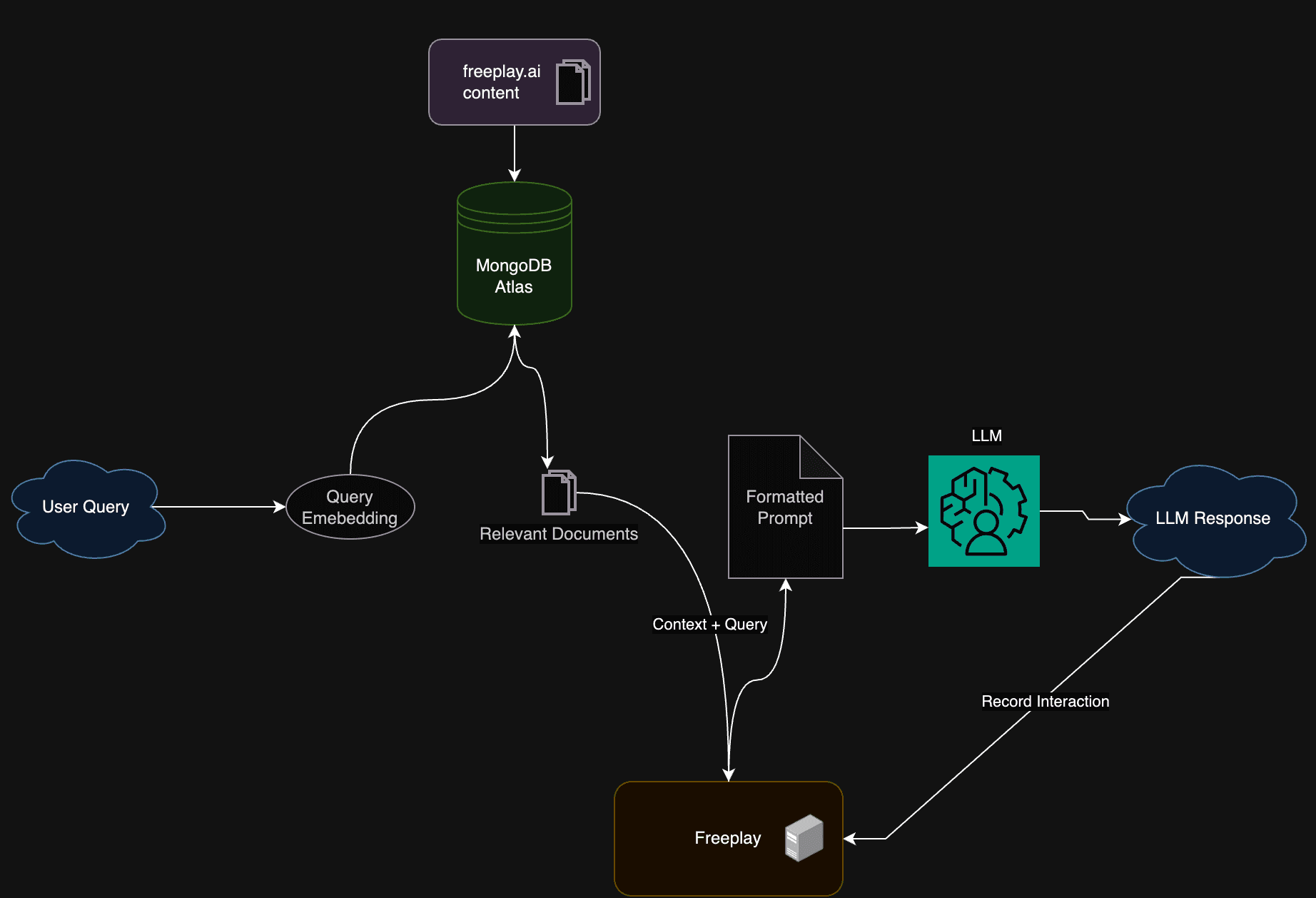
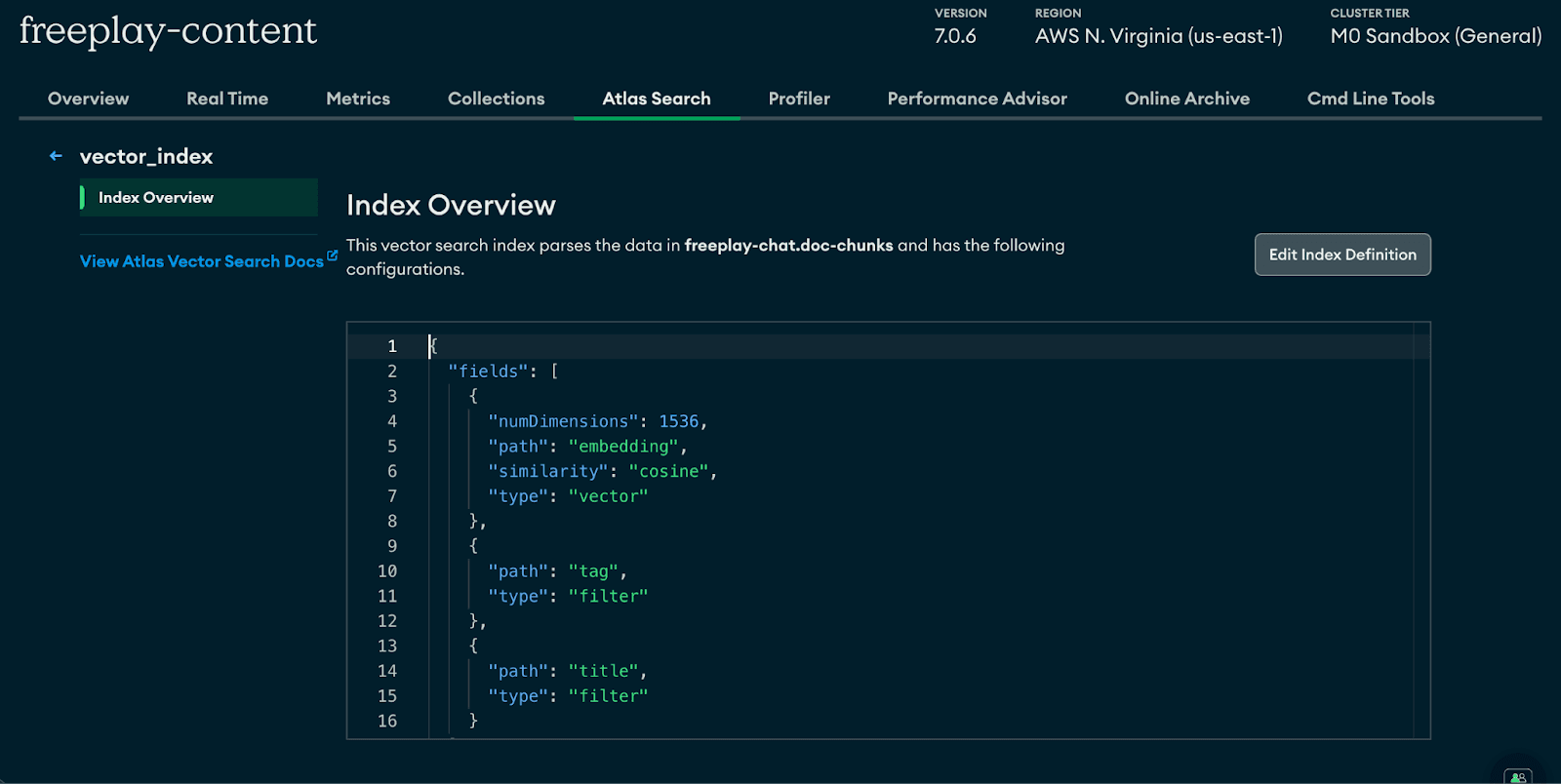
Step 1: Load content into MongoDB and Create a New Embedding Index
The beauty of MongoDB is being able to store your operational data alongside your embedding index as opposed to having to manage those two things across separate platforms. Their docs go intro greater detail:
If you don't have a MongoDB Atlas account, start here
Then: Fetch, chunk, embed and load data into your Mongo database. A sample code snippet is below.
Step 2: Configure your Prompt and Evaluation Criteria in Freeplay
See our guide here for configuring a project in Freeplay, from Prompt Management to Evaluations.
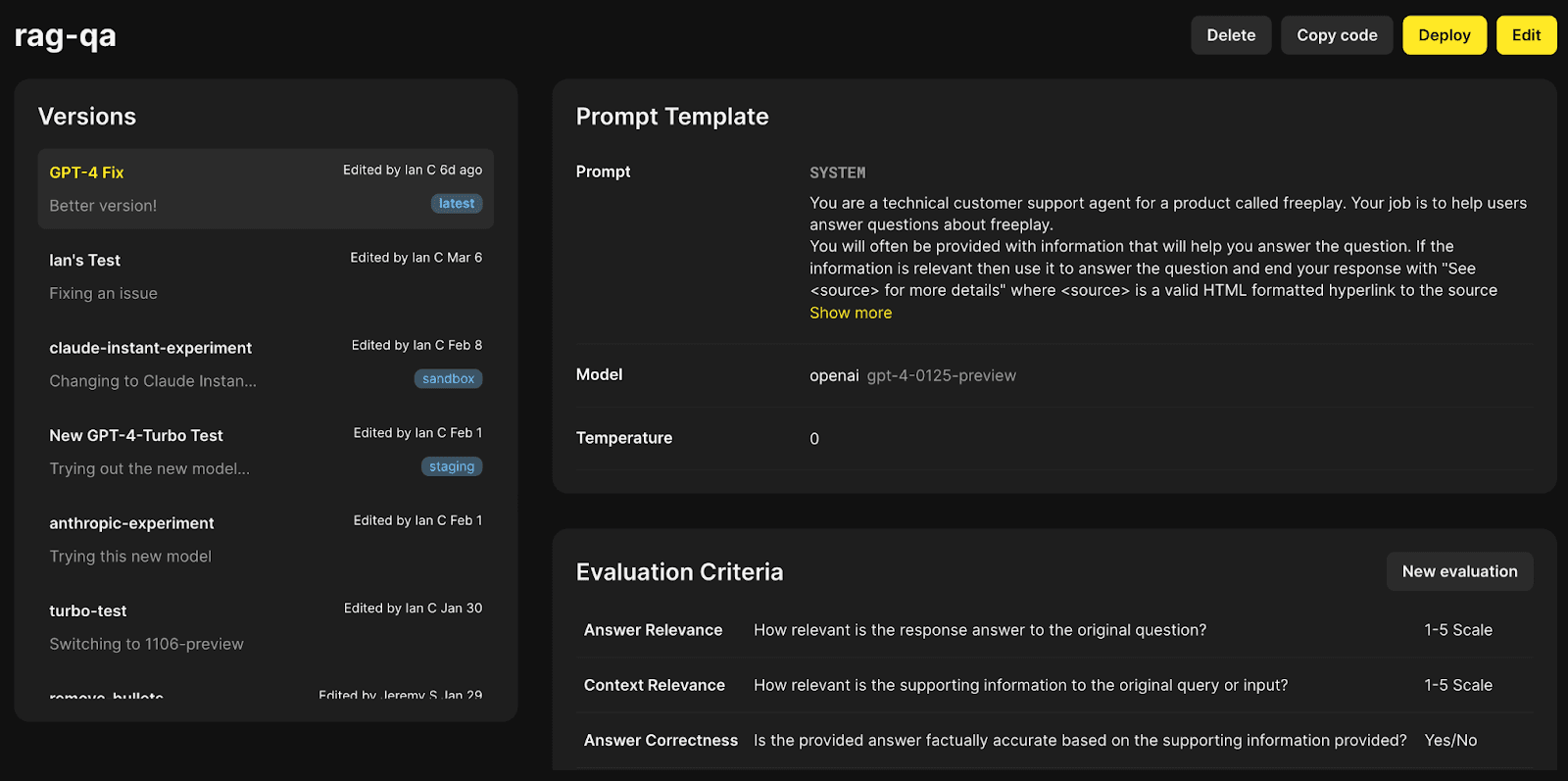
Screenshot of prompt versions & evaluations configured in Freeplay.
Step 3: Integrate your Application Code with Freeplay and MongoDB
Freeplay and MongoDB both offer a number of SDK languages. In this case we will be using Python. Freeplay also has full SDK support for Typescript and the JVM, as well as an API for customers using other languages.
MongoDB Integration
MongoDB’s SDK for vector search follows the same patterns as their traditional document stores making it very easy to pick up.
There are a number of knobs to tune on your Retrieval pipeline. They fall into two major buckets:
Chunking and Embedding Strategies – How you chunk and embed content
In this example, we’ve opted for a chunking strategy that roughly breaks documents in paragraphs.
We’re using OpenAI’s embedding model to generate embeddings.
Retrieval Parameters – Parameters that directly impact vector search results
Top K controls how many documents are returned during vector search.
Cosine Similarity Threshold controls the threshold for how similar a document embedding has to be to the query embedding to be included in results
We’ve started with some reasonable default values for each of these, but this is a big lever to pull when tuning your RAG system. Chunking strategies, different embedding models, and search parameters can yield markedly different results. It’s important to track these things with your experiments, which can be done by logging Custom Metadata in Freeplay. An example is below.
Freeplay Integration
Freeplay offers a flexible, lightweight SDK that is optimized for developer control — keeping core application code fully in your hands without wrappers or proxies. We’ve focused on making it easy to integrate with existing projects, without having to significantly re-work code.
Simply fetch and format your prompt/model configuration from Freeplay, make your LLM call directly with your API key, and record the results back to Freeplay. Here's another example.
Evaluate, Monitor, and Optimize
Once integrated, all the LLM interactions and RAG retrievals in your product will be recorded to Freeplay. You can record single completions, chains of completions, multi-turn chat, etc. as "Sessions" in Freeplay.
As Sessions get recorded, you can label them with human or model-graded evals (both using the same criteria), curate them into datasets for batch testing, and pull them into the playground to iterate on prompts with real data.
For a RAG system, it’s particularly helpful to create RAG-specific model-graded evals (like Context Relevance or Answer Faithfulness) that help identify issues with retrieval or hallucination. Those evals can then run on a sample of live production data as well, so you can have a pulse on how your LLM systems are performing in production — not just on static test sets.

Snapshot of Freeplay monitoring dashboard.
Together this system gives you the ability to quickly spot issues and fix them. Two examples for our RAG chatbot are below.
1. Uncovering & Fixing Poor Document Retrieval
As mentioned above, there are a lot of knobs to tune in a retrieval pipeline. Let’s say you’re noticing a lot of ‘Context Relevance’ scores below 3 — meaning there’s irrelevant content in our RAG results. We dig into those flagged Sessions and find there’s a lot of extraneous documents in our RAG results. We might want to address this by increasing our cosine similarity threshold, effectively raising the bar for relevance.
If we make a change to our pipeline like adjusting cosine similarity, we’d want to test that change against a benchmark dataset and compare the results side by side. Freeplay’s batch testing feature allows you to test against your datasets to benchmark and compare the performance of your pipeline. These tests can be initiated both from the UI or from the SDK, which is critical to test the change in your RAG pipeline.
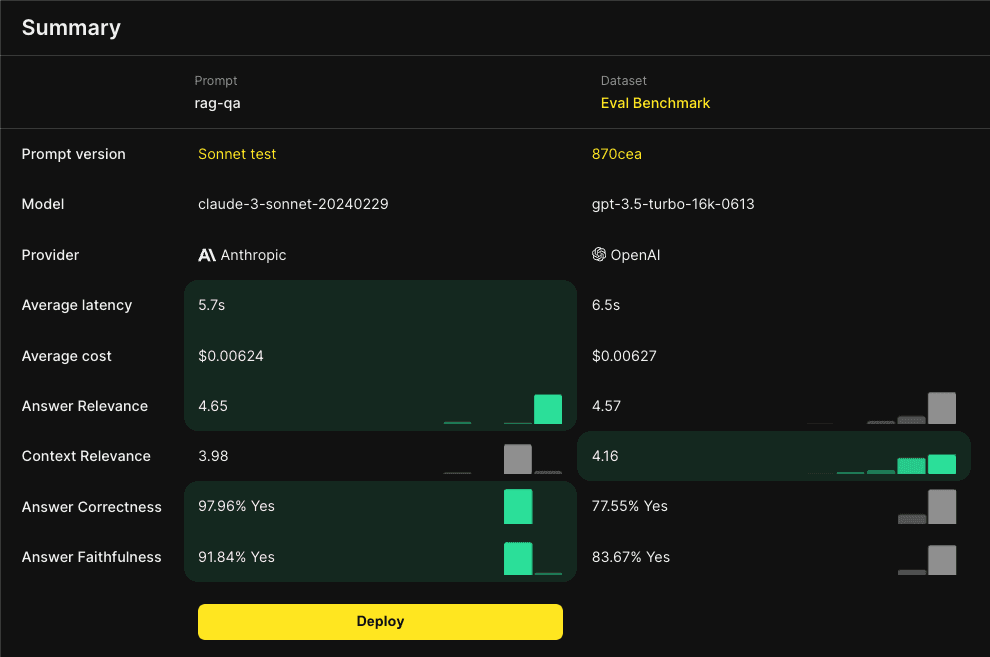
Screenshot of a completed test result in Freeplay showing Claude 3 Sonnet's improved performance.
Below is a code sample that shows what it looks like to create a Test Run using the Freeplay SDK.
2. Uncovering & Fixing Hallucinations in Production
You can easily use the Session dashboard to filter for sessions where Answer Faithfulness is “No”. This represents a hallucination because in effect the model is ignoring the provided information and hallucinating an answer.
Here I have an example where it looks like Context Relevance evaluated positively but the other criteria like Answer Faithfulness evaluated negatively. This indicates there was an issue with my generation steps rather than my retrieval step. Looking at the supporting information confirms this — we returned the right portion of documentation, but the model hallucinated an incorrect answer. It was not “faithful” to the provided context.
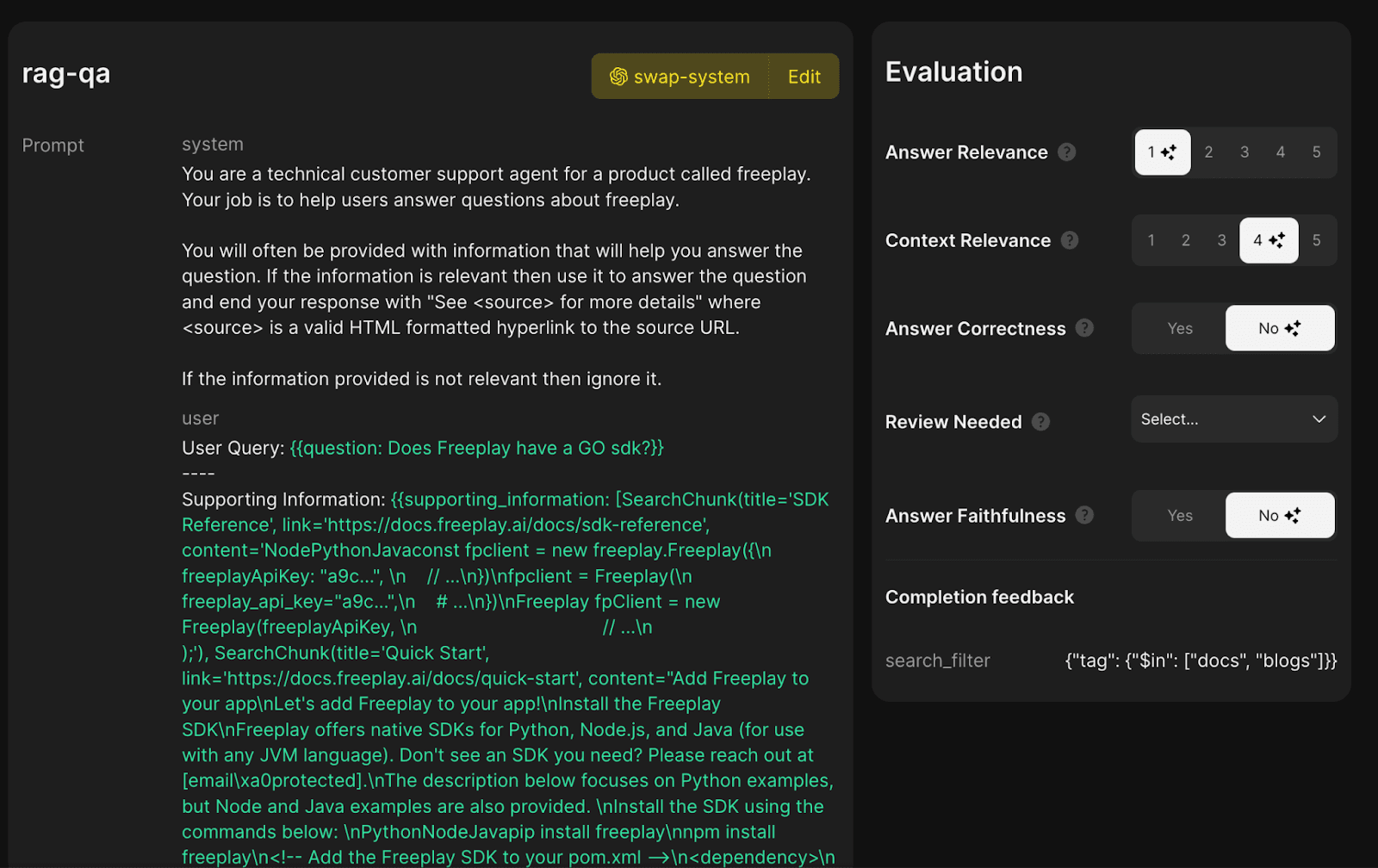
Screenshot of an auto-evaluated completion in Freeplay
But uncovering issues isn’t all that helpful if it’s not actionable! We can easily pull this example directly into the playground and experiment with ways to resolve the issue.
For example, we were using GPT 3.5 in this case, but in the Freeplay playground we can quickly see what happens if we were to upgrade the model to GPT 4. Additionally we could pull in other Test Cases from saved datasets and ensure we’re not over indexing on a single example.
In this case it looks like the hallucination was resolved by upgrading the model, and that trend held against other examples in our “Failure Cases” dataset. From here we could do further testing batch against our benchmark dataset or deploy the changes directly to a lower environment.
These are just two examples of ways Freeplay helps detect and address issues in RAG pipelines. With in-app testing, batch testing in code, and live production monitoring in place, you can have a powerful set of tools to uncover, diagnose, and address issues with your LLM application. Giving you the freedom to iterate as a team and ship with confidence.
With Freeplay and MongoDB working together in tandem you get a powerful toolset to bring your enterprise data to bear on your LLM applications.
Here's a video showing the end to end workflow.
Want to go deeper? Check out our docs here, or reach out here if you’d like to talk with our team.
First Published
Apr 4, 2024
Authors

Ian Cairns
Categories
Engineering