
A common story for AI engineering teams is that they hit a plateau a few months into production. They're iterating on an agent (tweaking prompts, adjusting retrieval, trying new models, adding tools), but they can't tell if they're actually getting better. Then they realize it’s time to invest in evals and a more structured approach to building their product.
The teams that break through this plateau usually figure out the same thing: they need to invest in their operational infrastructure (evals, test datasets, production traces) as seriously as they invest in the application itself. And for the teams that invest, they don't just skip the plateau – they move faster through every stage of development, including early prototyping.
This post breaks down what we mean by the “App Stack” and the “Ops Stack”, and explains why treating them as equally important parts of your product can help you build a high quality agent much faster.
————
We're three years into building production generative AI systems now. A pattern has become pretty clear: the teams that succeed treat their AI product as two distinct systems, each needing real investment.
The first is the application itself: models, prompts, tools, retrieval pipelines, orchestration logic. (The stuff that produces useful outputs.) This is where most teams focus, and for good reason. It's hard to get right, and the results are visible.
The second is the operational infrastructure: evaluators, test datasets, production traces, feedback loops. These are the things that tell you whether your outputs are any good and help you improve them. Traditional software has unit tests, integration tests, build systems... AI products need their own version of this, and it looks different enough that most teams have to figure it out from scratch.
The two parts of every AI product, defined
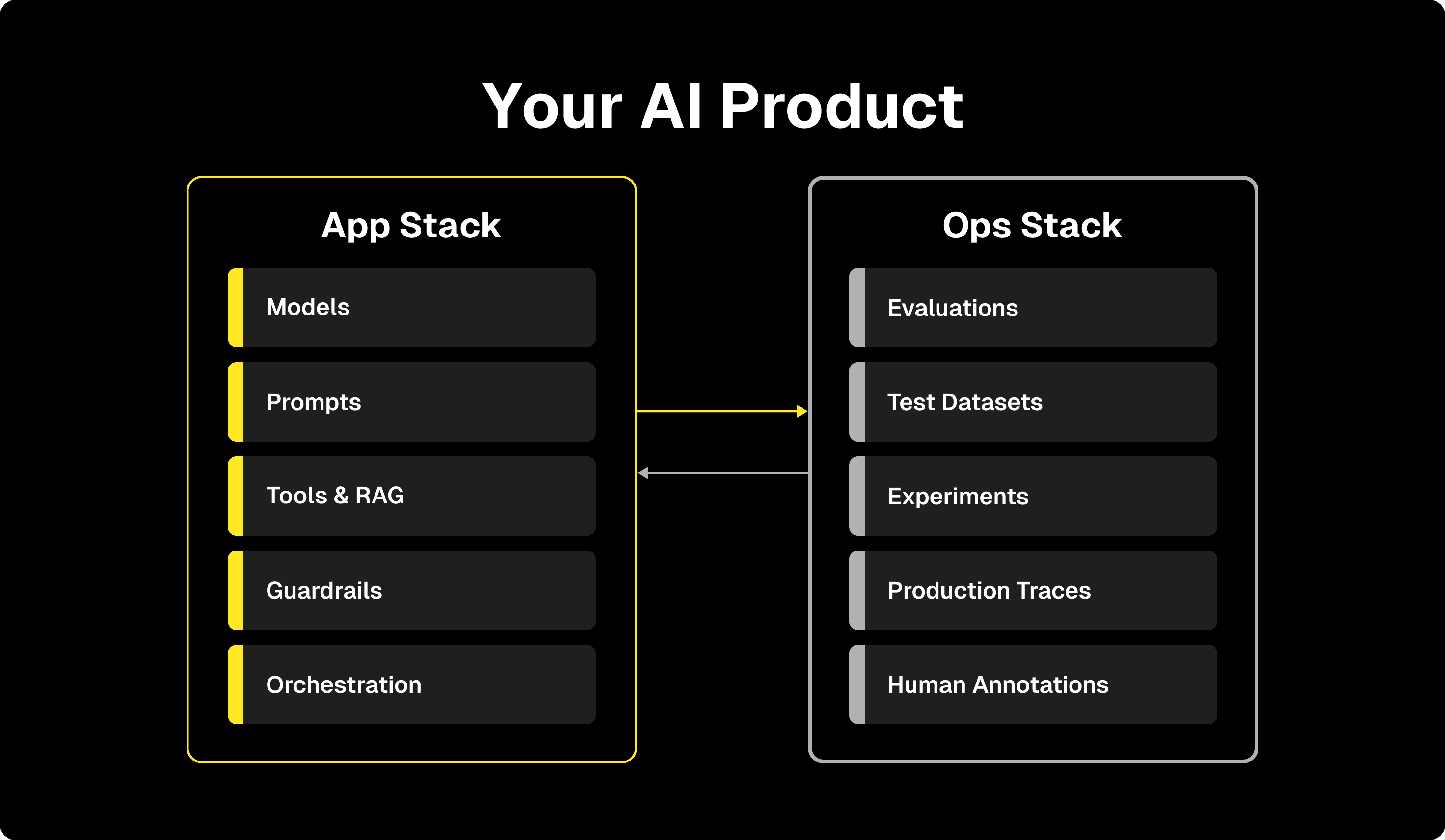
To be clear on our definitions in this post…
The App Stack is what makes your product run: prompts, tools, retrieval pipelines, orchestration logic. (The stuff that produces useful outputs.) Models provide inference. Prompts direct reasoning. Tools and RAG supply context. Guardrails enforce constraints. Orchestration logic handles control flow. This is what most people mean when they talk about "the agent." This is where most teams focus early on, and for good reason. It's hard to get right, and the results are visible.
This App Stack has seen enormous investment across the industry in things like models, inference APIs, orchestration frameworks, and infrastructure tooling. It's never been faster to build a sophisticated AI application as a result.
The Ops Stack is what makes your product actually good: evaluators, test datasets, production traces, feedback loops. Traditional software has unit tests, integration tests, build systems... AI products need their own version of this, and it looks different enough that most teams have to figure it out from scratch.
The Ops Stack helps you evolve your agent as models change, user behavior shifts, and your understanding of quality evolves. It’s also what lets you refactor your agent orchestration logic, adopt new tactics, and compare before/after results.
Evaluators define what "good" means for your use case, and these are often really specific to what you're building. We see customers defining criteria like "Did this auto-generated email address the right recipient?" or "Did this summary include the correct timestamp citations?" These custom evals end up being the key to real product improvement.
Datasets give you representative inputs and outputs to test against. Evaluations score new versions before you deploy. Production traces show you what's really happening out in the wild. Human annotations inject domain expertise where automation falls short.
This stack often gets far less attention until quality becomes the only thing that matters. Most teams cobble it together ad hoc, then rebuild it properly once they realize they have a problem.
The result is a predictable failure mode. Teams ship applications that look great in demos, then struggle to maintain quality once real users show up. Without systematic evaluation, every change is a gamble. Without production instrumentation, you learn about problems from customer complaints. Without representative test data, regressions ship undetected.
Why the Ops Stack determines velocity
There's a common assumption that this operational infrastructure slows you down, i.e. that evals and testing are overhead standing between you and shipping.
Often the opposite is true.
Teams without ops infrastructure move slowly because they can't take risks. Every prompt tweak might break something. Model upgrades require manual QA. Bug fixes are followed by anxious monitoring and hoping nothing else broke. The uncertainty accumulates.
Teams with solid ops infrastructure move faster because they can iterate without white-knuckling it. They can quickly test ten prompt variations and pick the winner. Upgrade to a new model on release day because the eval suite shows exactly what changed. Catch regressions in CI instead of production.
The pitch to engineering leadership writes itself: this infrastructure is what lets you ship continuously without accumulating quality debt. It's the difference between deploying weekly with confidence and deploying monthly with crossed fingers.
The maturity curve
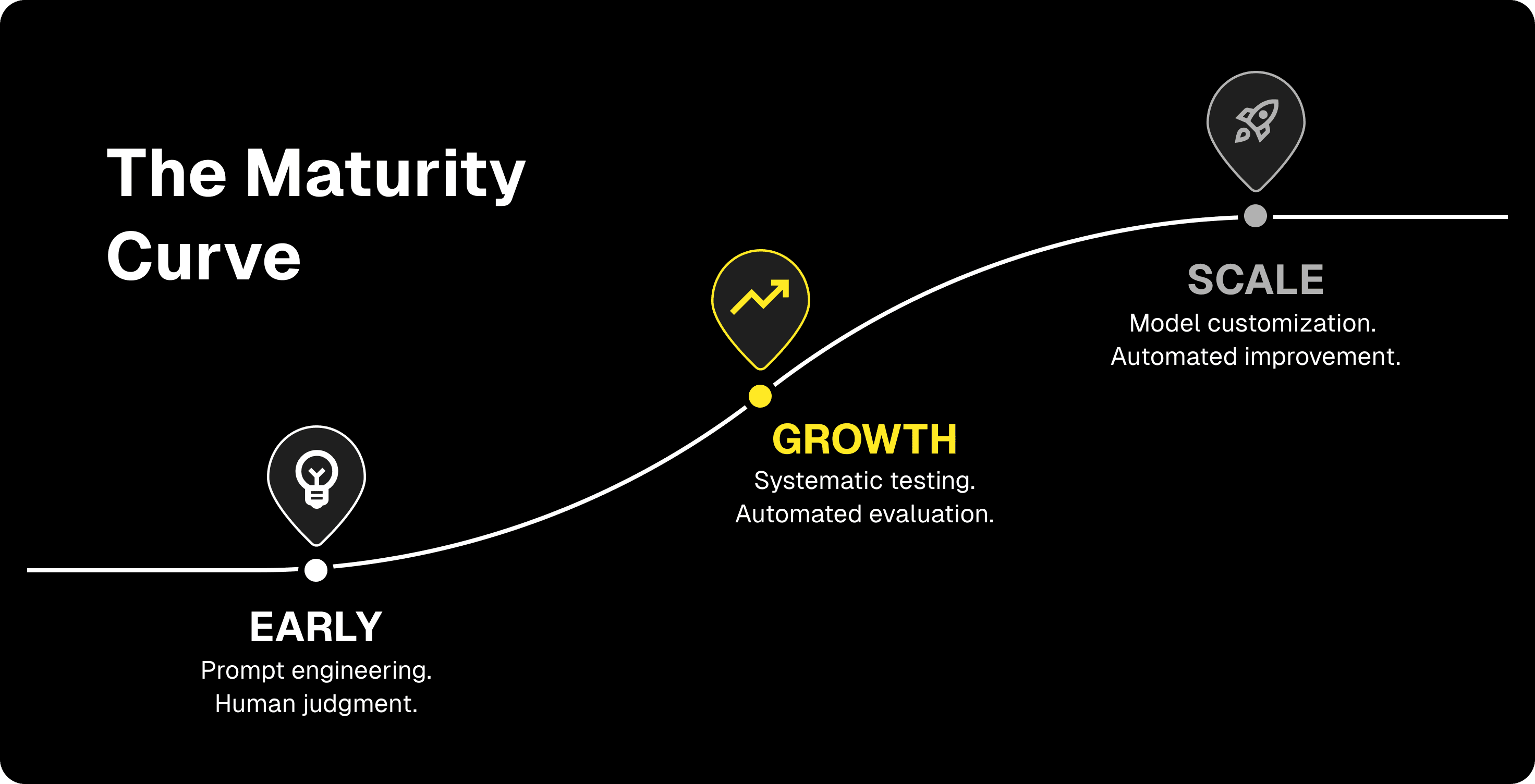
We tend to see teams move through predictable stages:
Early: Prompt engineering and context construction. This is the right place to start. Frontier models are good enough that thoughtful prompting and solid retrieval can unlock most of a use case's value. Human judgment and fast iteration are your main tools.
Growth: Systematic testing and evaluation. This is where teams often stall. You've got something working, but improving it further means pausing to build the ops infrastructure you skipped earlier. Once it's in place, iteration speeds up again.
Scale: Fine-tuning and optimization. With enough data and a proven use case, you can start thinking about fine-tuning and distillation to boost performance or cut costs. Don't start here—and it's nearly impossible to succeed at this stage without a strong ops stack underneath you.
The non-obvious thing: investing in ops infrastructure early doesn't just speed up this progression. It changes the shape of it. Teams with evals in place from the start make better decisions at every stage. They don't get stuck for months wondering if they're actually improving.
Making the case internally
If you're already bought in but need to bring others along, here's what we've seen land:
Evals are about speed, not just safety. Without automated evaluation, human review is the bottleneck and experiments are slow to run. With it, engineers can iterate on prompts and models independently, shipping when metrics pass instead of waiting for sign-off. Same shift CI/CD brought to traditional software.
Production data builds value over time, but only if you capture it. Every user interaction has signal about what's working and what isn't. Instrument early and you build a dataset that compounds in value. Wait, and you can't go back for what you missed.
Quality problems turn into business problems. Support tickets, churn, reputation damage… These are the costs of shipping without quality infrastructure. For leadership, ops investment is risk mitigation on one hand – you catch issues before customers hit them. But in terms of upside, it’s also the path to satisfied customers and products that deliver on business goals.
The data flywheel
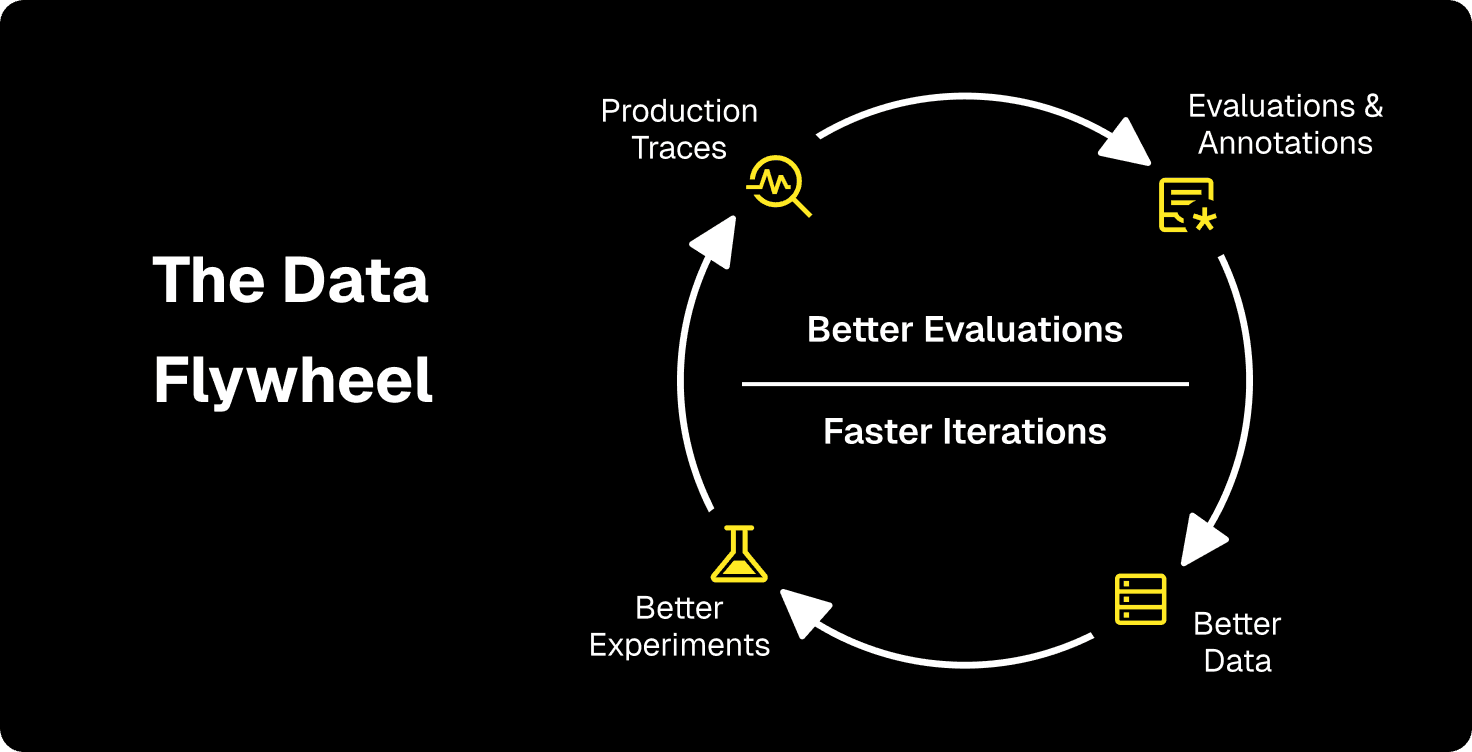
When both parts work together, you get a compounding loop.
Production traces surface real failure modes. Those failures become test cases. Evaluators score each new version against a dataset that actually represents production. Human reviewers refine what "quality" means. Each cycle produces better data, better evals, faster iteration.
Teams running this flywheel catch problems faster and learn faster . Every deployment generates insight that feeds the next version. Quality stops being a bar to clear and becomes a trajectory.
(We wrote more about this idea of iterating on your evals and test data quality in this post from June 2024.)
How Freeplay fits in
We’ve built Freeplay as the platform for your Ops Stack, so your team can focus on building AI products instead of on building evaluation and testing infrastructure from scratch.
The platform connects observability, evaluation, and testing into a single workflow:
Playground to production. Iterate on prompts and models as a team. Quantify the impact of any change. Deploy across environments with feature flags. Domain experts contribute directly; engineers control what ships.
Pre-deployment confidence. Run eval suites against real data before deploying any change to your prompts, models, tools or agent logic. Wire your evals into CI/CD to catch regressions automatically. Compare versions with actual metrics, not vibes.
Production visibility. Capture every LLM call, tool call, and agent step. Search across millions of logs. Auto-categorize traffic patterns and spot issues you didn’t even know about. Turn any trace into a new test case with one click.
Continuous improvement. Evals run in production for monitoring and offline for experimentation. Human feedback tunes and improves auto-evals. Production insights flow back into test data. Each iteration improves the next.
The teams using Freeplay succeed because they've invested in both stacks: the app that serves users and the ops stack that keeps improving it.
Both halves matter. Invest in them both.
If you're navigating these things now, we'd love to hear what's working for you and what isn't. And if you want help getting started, reach out. We're happy to talk through it.
First Published
Jan 9, 2026
Authors

Ian Cairns
Categories
Industry



