
Cisco Duo is a modern Identity and Access Management platform and market leader when it comes to multi-factor authentication and zero trust security solutions for organizations of all sizes. Cisco acquired Duo in 2018, and today Duo secures the critical identity layer as part of Cisco's security portfolio. It’s used by tens of thousands of organizations to verify user identity and secure access to applications.
Duo built its reputation as a security platform on reliability. From a brand perspective, they've always valued attention to detail and care for the end-user experience.
When Duo launched its agentic AI Assistant, the team set the bar at the same reliability customers expected from Duo, and then quickly learned they’d need a new operational process to get there. "That's really hard to do in generative AI," says Brianna Penney, Product Manager for the AI Assistant. "Building reliability, consistency… it requires a different kind of process."
More than a year ago, Duo published their approach to building a trustworthy AI assistant. This post is like a sequel: It's about how they've operationalized AI quality practices as a core part of their team culture.
A year in, the Duo team has figured out how to confidently ship and iterate on AI in production. Their AI product investment is increasing as a result, and they’re expanding access to their assistant to global customers.
Their hands-on, cross-functional approach allows each team member to contribute their expertise and perspective, and they've turned this collaboration into cadence so that they improve the customer experience a bit more each week. Their approach provides a roadmap for other cross-functional teams to borrow from.
A "Communal" AI Quality Practice
Much of the conversation around AI product development focuses on automated evaluation tactics: LLM-as-judge scoring, metrics dashboards, test suites, etc. These tools matter, but Duo's team discovered early that eval scores alone weren't enough to build a reliable assistant. Getting to reliably high quality levels requires people who know the product and the customer to look at real-world examples.
"(Looking at) review queues – getting in there and reviewing actual conversations – is the number one way to know how your experience is working," says Penney. "It's kind of the only way to do it, and you can't do it all with just auto-eval scores."
Their team built a cross-functional process where designers, product managers, data scientists, and engineers all participate directly in reviewing production conversations. Every week, each person reviews 15–20 conversations, then the team calibrates together on Fridays. Automated scoring and categorization tactics tell them what to look at, then they do the manual work together of reading through assistant conversations and agent traces in detail to understand why something went wrong or to spot emergent user needs.
"I would describe our process as communal," says Jillian Haller, Design Manager supporting the AI Assistant team. "We have rituals in place like Friday office hours where anyone who participates in labeling can meet and we label data together. It helps with alignment and standardization."
The team didn't have a blueprint for doing this kind of work when they got started. "We built all these processes without an example of how we were supposed to go about doing these things," Penney recalls. "We just started figuring it out. It was tough. And now it's interesting to see it validated in the market as best practice."
That validation is real. We see it across many Freeplay customers, and influential voices in the AI engineering community have been preaching the same message: the teams that actually ship quality AI products are the ones doing hands-on error analysis, not just building dashboards. See for example: Hamel Husain and Shreya Shankar, whose popular course on AI evaluation has trained thousands of practitioners (good summary here from their interview with Lenny Rachitsky).
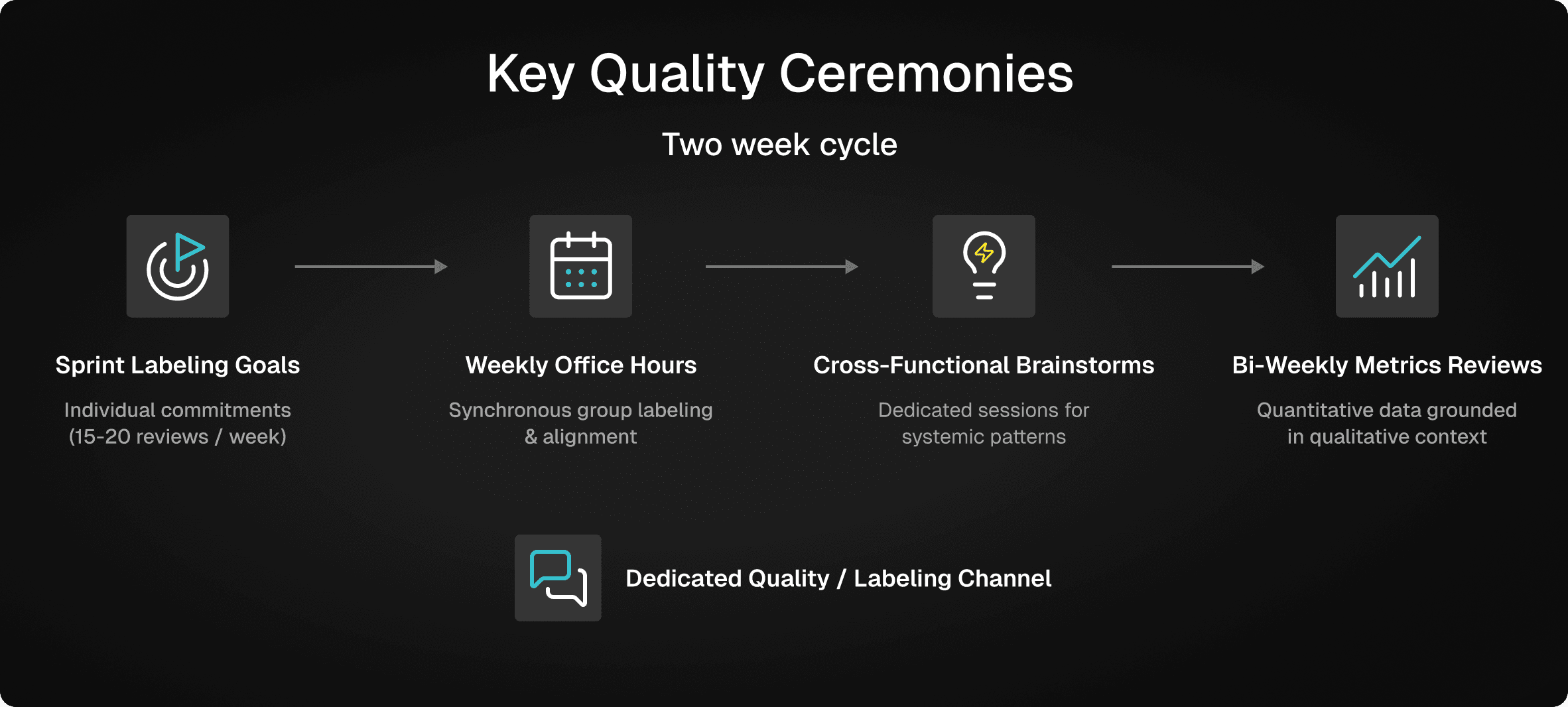
A year in, some of their team practices include the following:
Weekly Labeling Goals: Each team member (designers, PMs, data scientists, engineers) commits to reviewing 15-20 completions per sprint. As more people join, the individual load decreases. Even that much data can be tedious to look at, but it's attainable.
Friday Office Hours: A 30-minute weekly session where the team labels together, building shared understanding of quality standards and surfacing interesting patterns.
Dedicated Chat Channel: Team members doing async labeling can drop questions or surface interesting findings in a shared channel.
Cross-Functional Brainstorms: When labeling reveals systemic patterns or architectural questions, the team convenes dedicated sessions to brainstorm solutions outside of sprint planning.
Bi-Weekly Metrics Reviews: The team reports on quality metrics both internally and to leadership. They track things like "tool correctness" (did the assistant route to the right tool?), "appropriateness" (did it answer appropriately given the tools available?), "task success" (was the user's question ultimately answered?), and latency. They also run an automated evaluator to assess user satisfaction, and track retention rate and conversation length as proxies for whether users are getting value and building trust with the assistant over time.
Why Conversational Designers Belong in Production Data
One of the things that stands out most about Duo's process is the heavy involvement of designers. Multiple designers review production conversations regularly, and they've defined a new role for "conversational designers." These designers are thinking systemically about the conversational experience, spotting opportunities that pure metrics would miss, and contributing directly to product direction.
For the Duo design team, they don't see it as a side task or chore to analyze data from their assistant. It's a core opportunity to better understand their customers and the product.
"This is the next best thing to a contextual inquiry," says Haller. "We're actually able to see how the interaction unfolds. This is as close as you can get (to sitting) with a customer in their work environment.”
Compared to traditional qualitative research, the efficiency gains are significant. "Getting qualitative research done is pretty arduous," Haller explains. "With this, it's just logging into Freeplay and seeing the conversations. If we're thoughtful about how we look at different cohorts of people, we can extract great insights quickly."
Laura Cole, Lead Designer on the AI Assistant, has found that looking at conversation logs has changed how she thinks about her craft: "It helps me with pattern recognition: not thinking about users in an abstract way, but thinking about the actual interaction, the emotional state. I've had to really examine my approach. Figma is not the main event anymore. (Spending less time on pixels) frees me up to think about problems, which is what designers are supposed to do anyway."

From Conversations to Product Improvements: The Dead-End Agent
One example of how this works: The Duo team’s "dead-end agent" came directly from bottoms-up conversation review.
The "Dead End Agent" Problem & Solution
Before the GA of their assistant, Duo worked with a design researcher to synthesize assistant conversations from their beta period. A clear pattern emerged: users were hitting dead ends. When the assistant couldn't help with a request, it would simply say "I can't do that," and the conversation would stop.
"We were being super thoughtful about building trust," Haller explains. "We wanted to minimize wrong information. But we realized we could also make this failure more graceful and guide users to understand what the assistant actually can answer."
A vision became clear: Moving from a world where the assistant says “sorry, can't help” to where the assistant can say, “Sorry, I can't help with that exactly, but here's what I can do.” That way a user could keep making progress toward their goal.
Shakeel Davanagere, an engineer on the team, helped build the initial dead-end agent during an internal hackathon. When the main LLM can't answer with available tools, a secondary agent generates contextually relevant follow-up prompts based on the conversation history and the assistant's actual capabilities. Those appear as tappable buttons, keeping users in what Cole calls a "happy loop" rather than stuck. They’re able to keep making progress toward their goals.
"It reflects our brand values," Penney says. "Imagine you're shopping and you ask 'do you have this?' and they just say 'No' and walk away. That's a little rude. We want to be helpful even when we can't do something – be trustworthy, always guiding."
How Freeplay Enabled the Process
Duo's quality practice relies on tooling that makes cross-functional collaboration practical. They use Freeplay as that shared surface where product, design, engineering, and data science meet. "Freeplay is really our core tool for making product and UX decisions about how to improve the experience," says Penney.
Key ways the Duo team uses Freeplay:
LLM Observability: Before Freeplay, conversation review happened in spreadsheets. "We had visibility, but we didn't have any organization around that visibility," Penney recalls. Freeplay features like saved searches and review queue features made it practical to monitor and review specific problem areas.
Review Queues as the Core Surface: Managers curate samples of production data, and the cross-functional team works through them together to make sure everything that matters has human eyes on it. More on review queues here.
Auto-Categorization and Evaluators: The team uses automated evaluators and Freeplay’s auto-categorization feature to pre-tag conversations, like marking conversations as "tool needed" when the assistant couldn't fulfill a request. But they don't stop there: manual labeling validates (or corrects) automated scores and provides context that automation can't. More on the human score correction or “alignment” workflow here.
Engineering Debugging: "(Freeplay) became the go-to tool to debug any issues," Davanagere says. "You can see at what phase of the interaction there's been a failure: is it Bedrock, or is it our internal tools?" Freeplay’s observability features make it especially easy to dig into multi-turn conversations via Freeplay Sessions.
The Payoff: Confidence, Speed, and Expanding Investment
After a year of running this process, what has it meant for Duo?
Faster prioritization. Patterns from labeling directly inform the roadmap. When the team notices something like frequent entity recognition failures (the assistant struggling with misspelled usernames, for instance), they can easily quantify how often it happens and prioritize engineering work accordingly.
Shorter feedback loops. Features like the dead-end agent went from insight to hackathon prototype to production in weeks, not months. Their cross-functional process means design, product, and engineering are aligned before work begins.
Leadership confidence. The bi-weekly metrics reviews give leadership clear visibility into assistant quality. The team can point to specific metrics like tool correctness, task success, or user satisfaction, and ground those numbers in real conversation examples.
Happy users and continued investment. Perhaps the clearest signal: enough satisfied users that Duo’s AI Assistant investment is expanding. They're rolling out their assistant globally now including to Asia-Pacific customers, and the AI team at Duo continues to grow. The process they've built gives them the operational foundation they need to scale.
What Duo Has Learned About AI Quality
After a year of running this process, Duo's team has developed clear convictions about what goes into building high-quality AI agents. These are strong recommendations for other teams to consider in their own context:
Get cross-functional early. Designers and PMs can help spot patterns that engineering teams might miss, like emergent user needs, qualitative signals, or other user experience issues that don't show up in metrics.
Build rituals, not just dashboards. Practices and ceremonies like weekly labeling sessions, shared channels, and regular metrics reviews create habits that can matter as much as tooling. Consistency compounds.
Don't outsource quality. The people with the most insight into the customer experience should be looking at real data directly, not just reviewing reports from a support function.
Iterate on your Ops process. There's no standard playbook yet for AI product ops. Duo figured it out by doing the work, and now they're seeing their learnings validated as industry best practice. They got there by paying attention to how they work together as a team, and then iterating on that process.
For AI teams figuring out how to get AI agents to perform well in production, Duo's approach offers something increasingly rare in the hype cycle: proof of what actually works. The answer isn't a single technical decision or a one-time investment. It's an ongoing practice that’s communal, cross-functional, and continuous.
——
Duo uses Freeplay for observability, human review, and automated evaluation as part of their AI quality practice. Learn more about Freeplay.
First Published
Jan 26, 2026
Authors

Sam Browning
Categories
Case Study



