
Prompt engineering and model selection are the foundational building blocks for defining how your AI product will behave, no matter what you're building with LLMs (RAG systems, agents, etc.). While it’s easy to spin up ideas in a playground, many teams overlook the part that actually matters most for far too long: evaluation.
This post walks through how to use Freeplay for a much faster and higher-confidence prompt engineering and iteration loop — combining a powerful playground and product-specific evals to easily quantify any change to your system.
If you’re building an AI application that requires production-worthy quality, you need a process that helps you make quantifiable decisions about whether your prompt is getting better or worse, and about which model is best. Vibes alone will only get you so far.
Freeplay’s playground makes it easy to evaluate your prompts, tool selection, and model behavior in minutes using your own data as test cases. Once you have a good candidate, you can quickly launch offline experiments (or "tests") with hundreds or even thousands of tests cases and quantitatively compare each version using evals you define for success criteria.
And: No code is required to start! If you're in a non-engineering role, you don’t have to wait on an engineer for access or wire up a pipeline to begin. Go from idea to quantifiable decision fast and bring your whole team along with you. Any prompt engineer can start running custom evals in ~5 minutes.
Check out the demo video below, and get started for free here. Read on for details.
Evaluations as a Product Discipline
Prompt outcomes can be unpredictable. Slight wording changes, model updates, or temperature tweaks can create wildly different results. If you’re not testing changes quantitatively, you’re guessing — and you'll be much slower at deciding if a given change is better or worse.
That’s why the best AI teams will tell you that evaluation isn’t optional, it’s foundational to any AI product development process. In the words of long-time Google Cloud AI tech lead Kyle Nesbit:
"The most important thing when you start any machine learning or LLM project is you start with your evaluations. You start with the prompt formulation, what are the inputs my model will get, what the outputs will be, (decide) how is that going to drive a high quality user experience, and how will I characterize if the input data is good and if the output data is good… It's just framing the problem." (Watch the clip from our podcast)
The art of evaluation starts with defining the characteristics of a good user experience. And then it extends to something like unit tests in traditional software engineering — giving you instrumentation to know if your AI application is doing the right things, and help you catch when it's doing the wrong things.
Evaluating your prompts and model behavior helps you:
Quickly compare changes side-by-side as you version your system
Understand cost, latency and performance tradeoffs between models
Avoid regressions from new model versions or prompt changes
Choose what's ready to deploy based on large enough datasets to represent production
Try a New Model > Launch a Test > Decide With Data
Let’s walk through how to evaluate a prompt across different models in Freeplay. Each of these steps is covered in the video above too if you want to see it in action.
Step 1: Set up your prompt and upload a test dataset
Once you sign up for a Freeplay account, you'll land in the prompt playground. Paste the prompt you want to work on into the editor. This example generates social media posts.
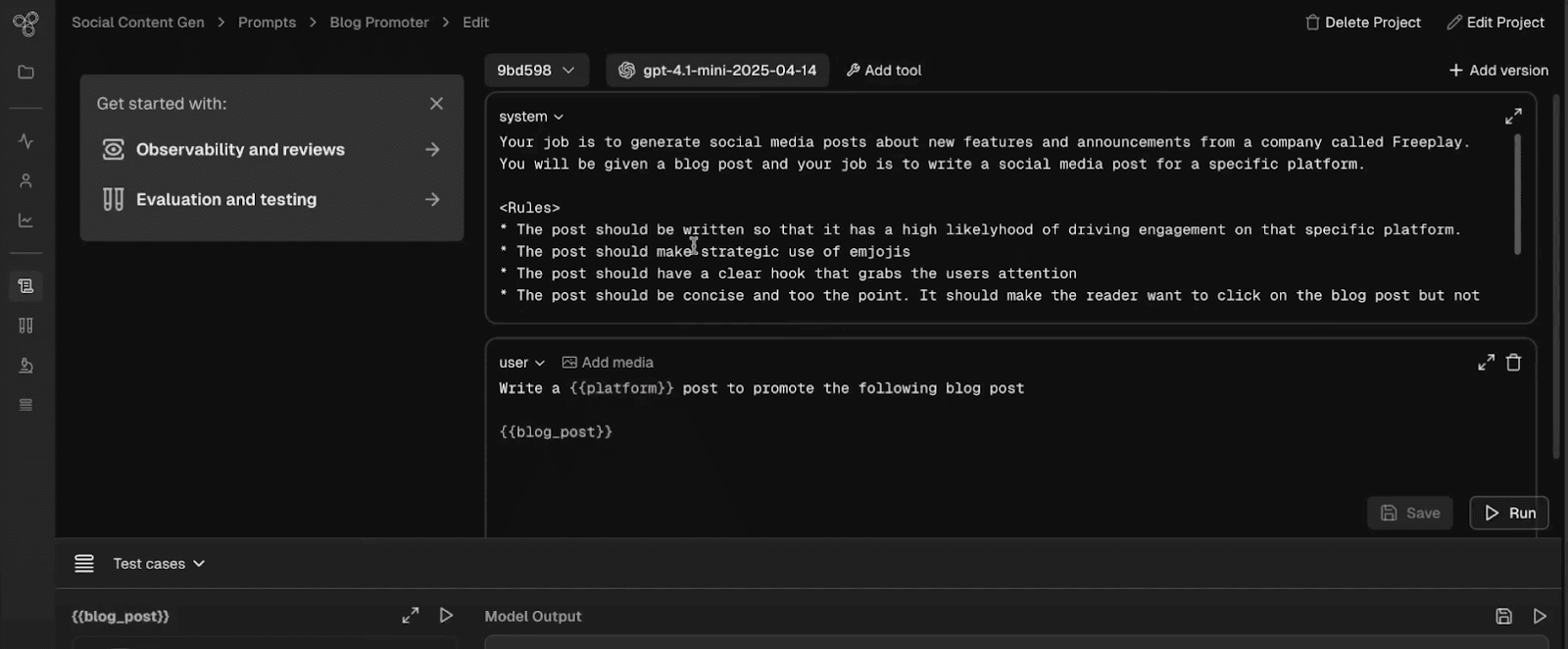
To test out your prompt, you'll ideally want to use real input examples from logs or user interactions (or else, make up examples on your own or with the help of an LLM). These examples will serve as tests cases as you adjust your prompt, and they represent the kinds of queries your app needs to handle - more on datasets here.
Once you upload some examples in a simple format like a CSV, they are accessible to use both in the playground and for evaluation. After you start logging data to Freeplay, you can also save any log data to datasets to supplement your test cases with real-world examples.

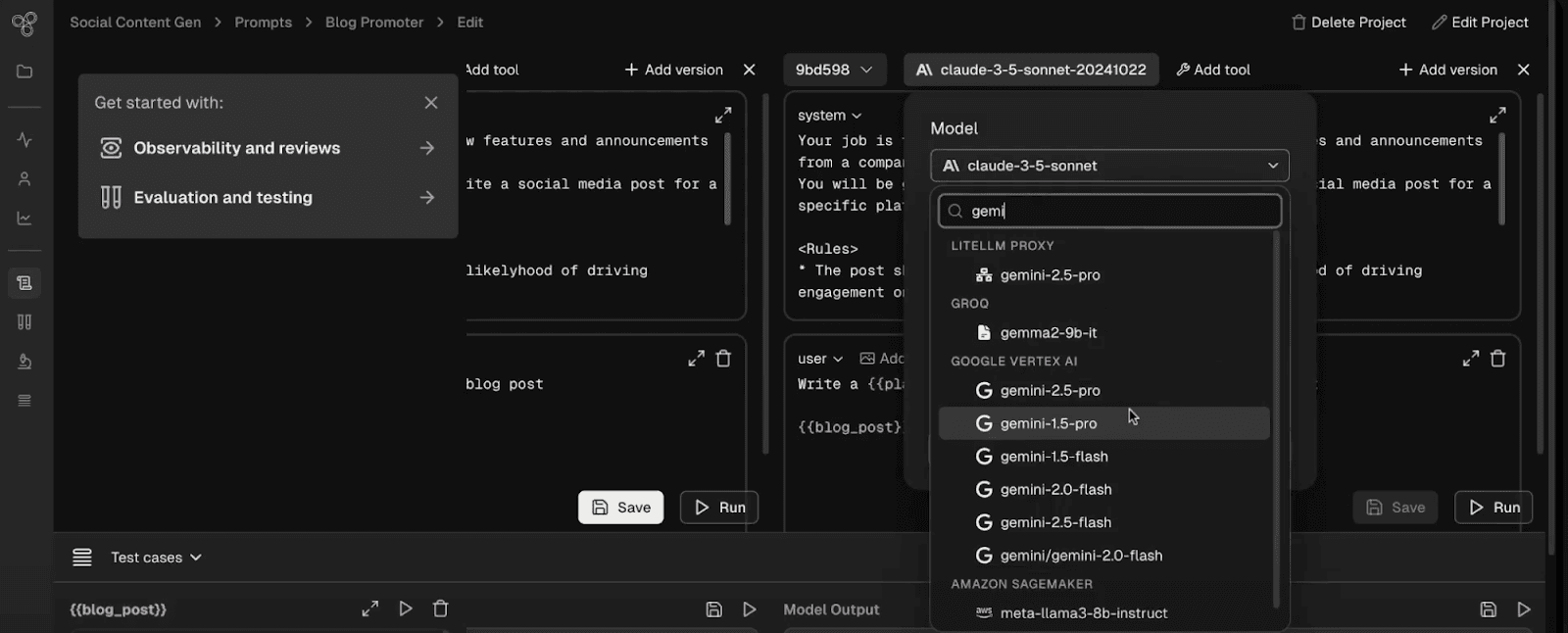
Step 2: Experiment with different model versions
From here you can hit "Run" in the playground to see how your prompt performs on the examples you selected. In this example, we've opened up multiple side-by-side columns to run our prompt through multiple models at the same time.
When you get to a version that looks good in the playground, save it so you can run it through all your evals in the next step.
Step 3: Set up evaluation criteria
Once you've saved the various prompt and model configurations that you want to test out, you'll need to create some evaluation criteria if you haven't yet.
When setting up new evaluation criteria, you can choose to score outputs manually (aka "human labels") or automatically, and define what criteria matter to you: things like relevance, format, tone, correctness, or anything else you define.
Our Freeplay assistant will even help you write a good eval if it's you're looking for help. Simply describe eval in your own words, and Freeplay will generate an eval prompt which can be customized further.
You'll likely want more than one eval. Many Freeplay customers start with 5-10 per prompt, and some quickly have dozens.

Step 4: Run a test to compare results side by side
With your initial evals configured, you'll want to run a test, which you can launch in three ways:
In the Freeplay app: From the Prompt page that you want to test, or from the Tests page.
Using the Freeplay SDK or API: Especially helpful if you want to test tool calls, agent orchestration, RAG retrievals, or other elements in your code (developer docs)
You'll select the dataset you want to use — this can include hundreds or even thousands of examples (however many you need to cover important customer use cases and edge cases). You can select multiple additional versions of your prompt to compare as well.
Once a test completes, you’ll be able to quickly spot where one performs better, worse, or breaks entirely across your different evals, as well as latency and cost.
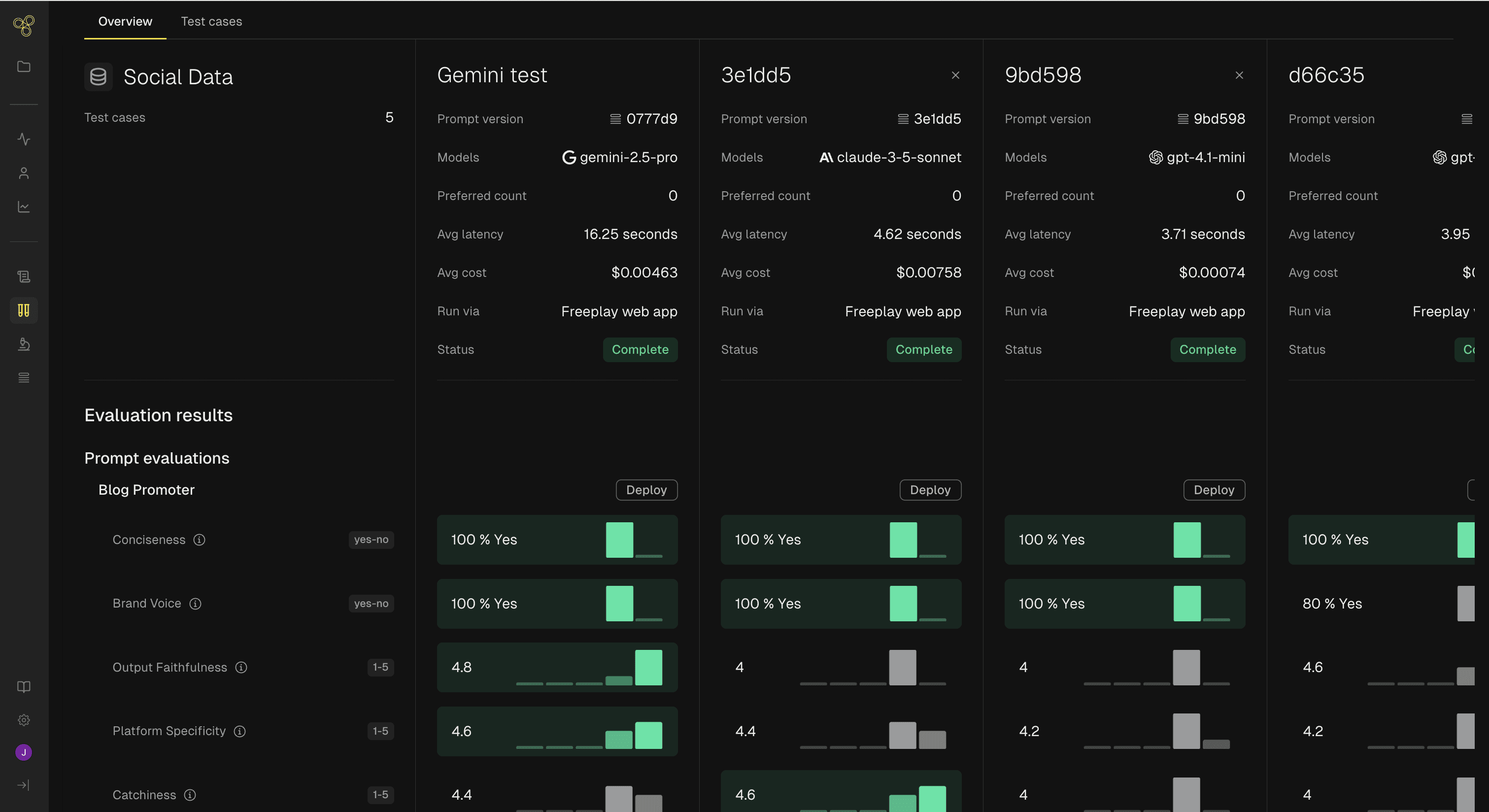
At the same time, we don't recommend you rely entirely on metrics. You can click into the row-level data at any time, and even make a human preference selection for which version you prefer. That feature is especially helpful when eval values are similar or differences are inconclusive.

From Playground to Production, Seamlessly
Once you’ve found a prompt and model combo that works, one of the best parts of using Freeplay is that you don’t have to update your code to move forward. If you're using Freeplay's SDK or API for prompt management, you can select the version you want to deploy in the Freeplay UI and it will update in the environment you choose — just like a feature flag. (Or alternatively: Our prompt bundling feature lets you check a prompt version into your source code.)
Together, these Freeplay features let you:
Quickly experiment with any prompt and/or model change
Write your own evals that are specific to your data and product context
Launch quantitative tests directly from the prompt editor that use your evals to score changes
Easily deploy changes to prompt and model configuration — without interrupting engineers
Every prompt and model and parameter combination is treated as a testable experiment. And everything you test can be logged, monitored, and re-evaluated later using your production data.
Built for Teams That Ship at Scale
Many teams we work with started out testing prompts manually — which worked until they needed to compare many versions to address bugs and customer feedback, integrate with real workflows, or make go/no-go decisions with quantitative data. Once you're operating at production scale, all of these abilities become essential. Otherwise you're stuck doing constant manual work to adjust and review each part of your system.
Freeplay helps engineers, PMs, data scientists, and domain experts stay aligned and work faster by sharing access to every experiment, prompt, and eval.
Get started with a free account to see how Freeplay can work for you and your team.
First Published
Jun 25, 2025
Authors

Jeremy Silva
Categories
Product




