
Chime has always defined itself by a singular mission: to be the most loved banking app by delivering helpful, transparent, and fair financial services. Their member-obsessed culture drives their approach to AI. Chime views AI as a tool to better support members through a whole range of use cases, from customer service to consumer product experiences to detecting and mitigating financial crimes.
This case study walks through the ways Chime’s Product, Engineering and Ops teams have been able to scale production AI use cases by taking an innovative approach to how they work. They’ve built an operational process that lets domain experts and engineers work closely together on AI product iteration, evaluations, and quality to deliver more AI projects, faster.
The Challenge: Delivering AI Quality At Scale
"The big story here is how we operationalize AI," says Chris Hernandez, Manager of Speech Analytics & AI at Chime, which sits within the wider Customer Experience Operations team.
"It’s fairly easy to have an idea and get a proof of concept running. The hard part is getting the model to produce what we want, at the scale we want. That is where our team (of domain experts) comes in."
Anyone building generative AI products in a complex domain will be familiar with the challenge. It’s helpful (and often, necessary) to involve domain experts at multiple points in the development process to get to a high-quality product. At the same time, engineering plays an essential role in building and instrumenting AI systems.
But there’s a gap: The two groups often aren’t used to working together, and they struggle to figure out everything from tooling to practical workflows for collaboration. It can frequently take weeks or more to go through a single iteration cycle as a result. And since all changes tend to go through engineering initially, they can often end up feeling like a bottleneck.
These challenges get exponentially harder to operationalize with a system that runs millions of times in production -- especially while maintaining the safety, accuracy, and trust that are essential in a regulated environment.
The Strategy: Empowering Domain Experts & Engineering Together
Chime’s AI leadership saw an opportunity to break this bottleneck. Starting in 2023, they’ve established a workflow where responsibility is shared:
Engineering builds the pipelines, infrastructure, and scales the system. They also instrument AI products so domain experts can contribute independently.
Domain Experts (Ops & Product) own the prompt performance, evaluations, and ground truth dataset curation. Together with Ops contractors, they review production examples at scale, identify issues, and propose fixes.
To make this collaboration possible engineers being responsible for every change, Chime standardized its AI product operations on Freeplay.
"We have a lot of humans here that are very sharp and passionate about building better member experiences," says Dennis Yang, Principal Product Manager for Generative AI at Chime. "Tools like Freeplay give them a really critical role to play in this whole process."
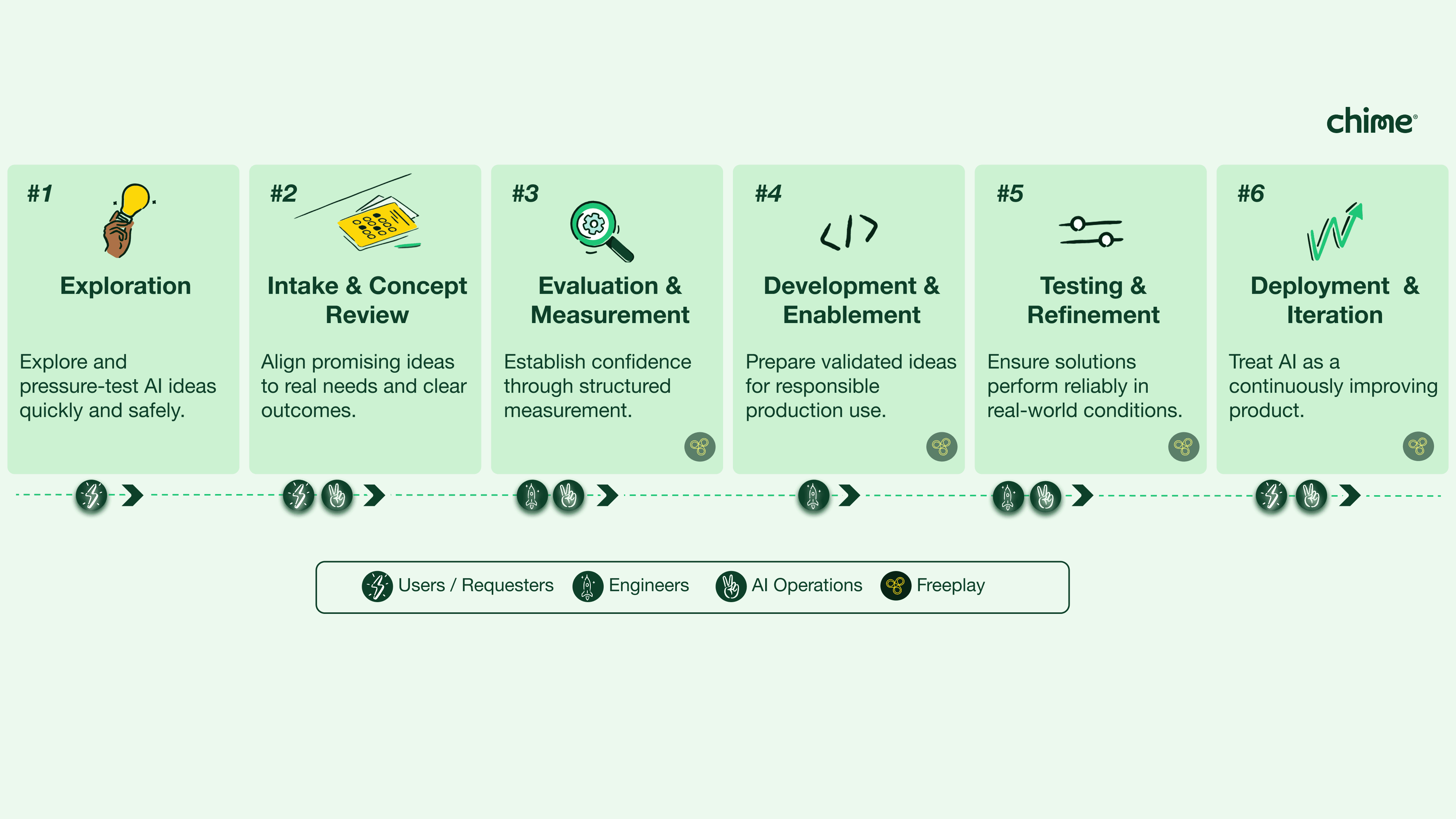
Here’s what that AI product operations process looks like today:
Phase 1: Exploration - Anyone with a good idea is encouraged to prototype ideas directly in tools like ChatGPT before writing a line of code.
Phase 2: Submit Promising Ideas - Once a concept proves viable, domain experts are invited to start doing the work to scale it up. They begin by curating golden datasets in Freeplay.
Phase 3: Evaluation - Once a golden dataset is developed, domain experts partner with Chris’ Speech Analytics & AI team to develop custom evaluation pipelines to measure quality at scale.
Phase 4: Development - When initial evals start passing, the production engineering team gets involved to operationalize the proof of concept. They set up prompt management so that domain experts can ship prompt and model changes on their own.
Phase 5: Testing & Production - Domain experts then work together with the Speech Analytics and engineering teams to test and refine the production version.
Phase 6: Deployment - Once live, the Ops team takes over working with the domain expert(s) to regularly review production data and develop ideas to improve.
Chime’s internal PromptOps Framework
Real World Examples: Automating Financial Crime Investigations and Voice of the Member Insights
One of Chime’s most impactful AI applications involves their Financial Crime team, which handles Anti-Money Laundering (AML) processes. Historically, this required heavy manual lifting by BPO agents to capture data and write investigation reports.
Akshay Jain, a Staff Engineer on the ML Platform team, spearheaded a project to automate this report generation. While he initially built the relevant prompt pipelines, maintenance has now shifted entirely to the non-technical domain experts from the Financial Crimes team.
“Our (ML Platform) team focuses on building data science and machine learning solutions. We started with initial prompt building and thinking through what sort of evaluations we need, then setting up evaluations and review queues in Freeplay and onboarding a QA team that goes through QA every day. And we use Freeplay to debug and troubleshoot.”
Akshay continued: “Now, slowly we are shifting prompt changes and evaluation management to the domain expert team because they are closer to the domain. They had never done any software or AI work at all. Now they’re getting into that place where they manage human review queues, evaluations, and even small prompt changes."
The Impact:
40% Efficiency Gain: Average case handling time dropped by ~30 minutes per case.
Superior Quality: Automated reports now score 99.2% to 99.5% on quality audits, outperforming human agents where language barriers often caused variability.
OpEx Savings: The project resulted in millions of dollars in OpEx savings, allowing capital to be reinvested elsewhere.
Chime applied this same methodology to their Voice of the Member program, where they need to analyze member feedback surveys.
"We had a dedicated review team spending 40 hours a week, each person manually tagging every single transcript that came into the business," says Hernandez.
By moving this workflow to an LLM-driven process managed in Freeplay, Chime fully automated the tagging and freed up those domain experts to work on higher-leverage tasks.
To maintain accuracy as member feedback trends change, SMEs use Freeplay to review production data, and then update their "Golden Set" of ground truth data when they find interesting new examples -- ensuring their model evolves alongside their customer needs.
The Outcome:
Cost Savings: Hundreds of thousands of dollars in operational savings.
Re-deploying Talent: a dedicated review team responsible for data review in the past are now able to focus on other, higher-leverage work.
Scale & speed: The system now processes surveys instantly without the bottleneck of human tagging.
How Freeplay Helps
Chime uses Freeplay as the collaboration layer where Engineering, Product, and Operations meet. Here are three big ways they use the platform to drive quality:
1. Democratizing Prompt Engineering
Using Freeplay’s prompt management features, anyone on the team has the opportunity to spot an issue, iterate on prompt and model changes in the Freeplay playground, run an evaluation, and decide whether a new change is ready to ship to production. When a domain expert tags a new version to deploy, Chime engineers have built a release management process that automatically pulls into release pipelines and gets it out the door.
2. Human Review at Scale
Well-defined evaluations are key to iterating confidently on an AI system. But evals are often limited to a few hundred or maybe a few thousand examples. When a system runs millions of times, it’s essential to look for the “unknown unknowns” and understand where real-world behavior might be different from test scenarios. Chime routes all their production logs to Freeplay’s Observability feature, where managers can then curate data samples into Review Queues for detailed review and annotation. Learnings from those reviews fuel not just prompt and model iteration, but changes to evaluation metrics and datasets as well.
3. Evals & Curation of "Golden Sets" (aka Ground Truth)
To know if an AI model is accurate, you need a standard of truth to test against. At Chime, they call this their "golden set." But with production systems, that golden set needs to evolve over time to match production realities. Domain experts use Freeplay to review production examples as part of standard QA, but then when they find interesting or relevant new examples, they can also add those directly to their golden sets -- effectively keeping their evaluations up to date with what "good" looks like as usage evolves.
A Shared Platform to Scale AI Engineering
Chime has successfully moved beyond the "science project" phase of applied AI. By using Freeplay to bridge the gap between technical implementation and domain expertise, they have operationalized AI at scale and created additional bandwidth to pursue more strategic projects.
For Yang, that’s the goal: leverage (not just efficiency). “Cost savings is not why we do these projects. It's so that we can do better work and more of it for our members. We can do a better job for our members even as our business continues to scale at such a rapid pace.”
With many users all across Chime using Freeplay, the platform serves as the collaboration layer where Engineering, Product, and Operations meet.
By empowering the people who know the customer best to build the AI that serves them, Chime has established a new standard for the modern AI organization.
———
*Chime is recommended by more of its users than other financial brands in the survey per 2024 Qualtrics® NPS score.® Trademark Chime Financial, Inc.
First Published
Jan 14, 2026
Authors

Sam Browning
Categories
Case Study




